OpenClaw系列第16课:sessions_spawn - 怎么派生子 Agent

OpenClaw系列第16课:sessions_spawn - 怎么派生子 Agent
Kai这是「OpenClaw 教程课程」第 16 课。
从这一课开始,我们进入第四模块:多 Agent 与自动化。前面几课讲的是工具能力;从这里开始,我们讲怎么让多个 Agent 协作,把任务拆出去、跑起来、再把结果收回来。
图:sessions_spawn 可以把一个明确任务派生给子 Agent,让它在独立会话中后台运行,完成后再把结果回传给主对话。
很多人刚开始用 OpenClaw 时,所有事情都让当前这个 Agent 做。
这当然没问题。
但当任务变复杂后,你会遇到几个很现实的问题:
- 当前对话被一个长任务卡住
- 查资料、跑测试、写总结不能并行
- 一个任务需要多个方向同时探索
- 主对话里不想塞太多中间过程
- 某些工作适合隔离出去,避免污染当前上下文
这时候,就需要子 Agent。
而 sessions_spawn 就是用来派生子 Agent 的工具。
这一课我们讲清楚:
sessions_spawn 是什么,什么时候该用它,怎么写好子 Agent 任务,以及怎样避免多 Agent 失控。
一、sessions_spawn 是什么?
sessions_spawn 是 OpenClaw 里用来启动子 Agent 的工具。
你可以把它理解成:
主 Agent 把一个明确任务交给后台同事去做。
这个“后台同事”就是子 Agent。
OpenClaw 文档里说,子 Agent 是从已有 Agent run 中派生出来的后台 Agent run。
它会运行在自己的 session 里。
常见 session key 形态类似:
1 | agent:<agentId>:subagent:<uuid> |
这说明它不是主对话里的一段临时思考。
它是一个独立的会话。
它可以自己读文件、查资料、执行允许的工具、整理结果。
完成后,再 announce 回请求它的主对话。
二、为什么要派生子 Agent?
最核心的原因是:
把适合独立完成的任务拆出去。
1)避免主对话被长任务卡住
比如你让 Agent:
1 | 帮我查完整文档,再整理 10 条结论。 |
如果全部在主对话里做,用户就要一直等。
如果派给子 Agent,主对话可以继续处理别的事情。
2)并行处理多个方向
比如写一篇教程时,可以让:
- 子 Agent A 查官方文档
- 子 Agent B 查本地源码或配置
- 子 Agent C 整理旧文章风格
最后主 Agent 汇总。
这就是多 Agent 的价值之一:并行。
3)隔离上下文
有些任务会产生很多中间信息。
如果全部塞进主对话,主上下文会变乱。
子 Agent 独立运行,可以把探索过程隔离出去,只把最终结果带回来。
4)降低主 Agent 负担
主 Agent 可以更像项目经理:
- 定义目标
- 派发任务
- 接收结果
- 汇总判断
子 Agent 则负责具体执行。
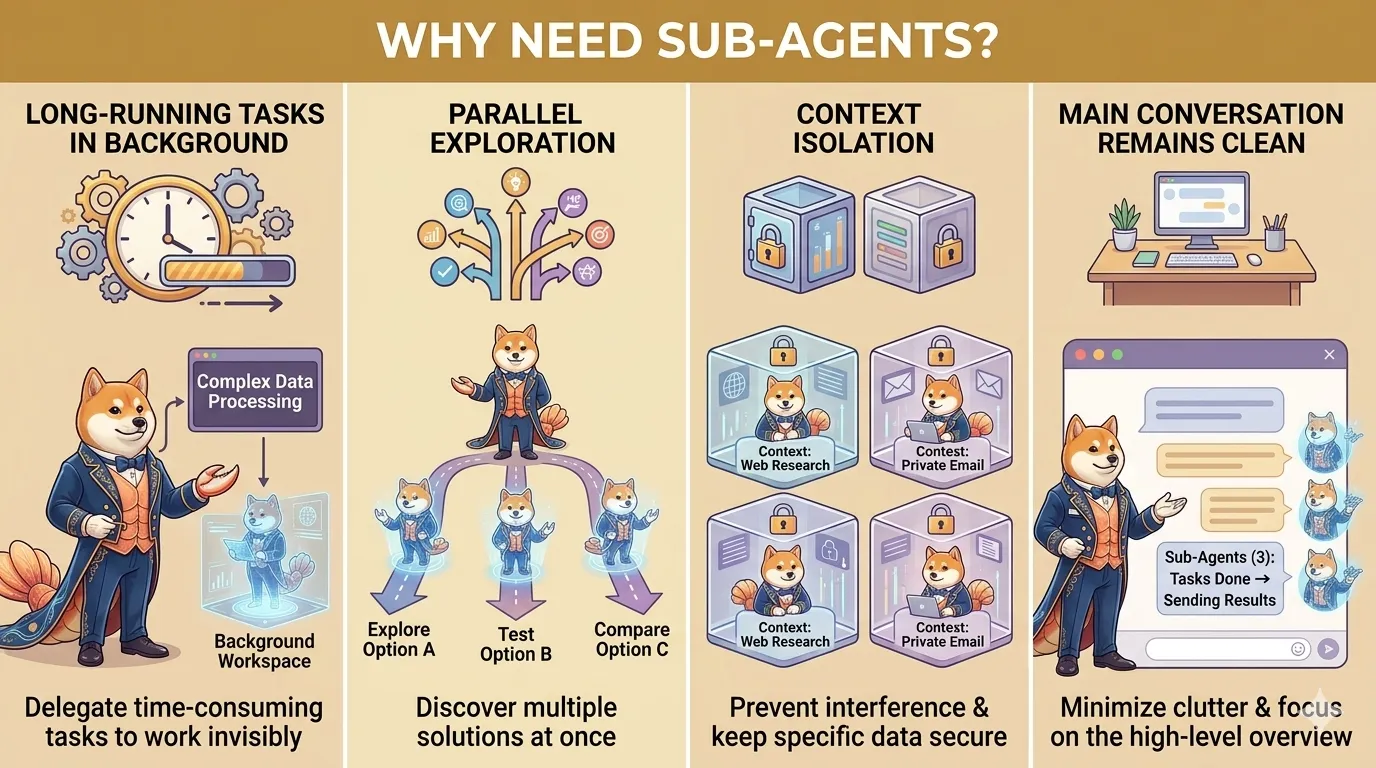
图:子 Agent 适合处理长任务、并行探索、隔离上下文和后台执行,让主对话保持清爽。
三、sessions_spawn 和 subagents 有什么区别?
第 17 课会专门讲 subagents 管理。
但这里先把最重要的区别说清楚。
sessions_spawn:负责启动
sessions_spawn 负责:
创建一个新的子 Agent 任务。
它解决的是:
- 派谁去做?
- 做什么任务?
- 用什么模型?
- 要不要带当前上下文?
- 运行多久算超时?
subagents:负责管理
subagents 负责:
管理已经启动的子 Agent。
它解决的是:
- 谁还在跑?
- 要不要补充指导?
- 要不要终止?
所以一句话区分:
sessions_spawn 负责“派出去”,subagents 负责“管起来”。
图:sessions_spawn 创建子 Agent;subagents 管理已经运行的子 Agent,包括查看、干预和终止。
四、sessions_spawn 是非阻塞的
这是一个非常关键的点。
文档里明确说:
sessions_spawnis always non-blocking.
也就是说,它启动子 Agent 后,会很快返回:
- runId
- childSessionKey
- accepted 状态
但它不会一直卡在这里等子 Agent 完成。
子 Agent 会在后台继续跑。
完成后,它会通过 announce 机制把结果回传给请求方。
这和普通函数调用不一样。
你不能把它理解成:
调用 sessions_spawn,然后马上拿到最终结果。
更准确的理解是:
调用 sessions_spawn,只是把任务派出去了;最终结果稍后推送回来。
所以使用子 Agent 时,很重要的一条原则是:
不要用轮询来等结果,等它完成后主动回报。
这点第 17 课会继续展开。
五、子 Agent 完成后怎么回来?announce
子 Agent 完成后,会走 announce 机制。
你可以把 announce 理解成:
子 Agent 回来汇报工作。
文档里提到,announce 会把结果发回 requester chat,也就是发起它的那边。
通常里面会包含:
- 任务结果
- 成功、失败、超时等状态
- 运行时间
- token 使用
- child session 信息
不过这些内部元数据不应该原样发给用户。
主 Agent 应该把它整理成自然语言。
例如内部结果可能是:
1 | Status: completed successfully |
用户应该看到的是:
1 | 子任务完成了。我找到了 3 个相关文档,重点如下:…… |
所以子 Agent 的结果回传不是“机械转发”,而是“汇总后交付”。

图:主 Agent 使用 sessions_spawn 派出任务,子 Agent 在独立 session 中运行,完成后 announce 回主对话。
六、什么任务适合交给子 Agent?
不是所有事情都要派子 Agent。
子 Agent 适合这些任务。
1)耗时较长的任务
比如:
- 搜集资料
- 分析日志
- 跑长测试
- 整理大量文件
- 阅读多篇文档
这些任务可能需要一段时间,适合后台做。
2)可以独立描述清楚的任务
比如:
1 | 请阅读 /usr/lib/node_modules/openclaw/docs/tools/tts.md,整理 TTS 的 provider、命令和自动触发规则,输出 8 条以内结论。 |
这个任务边界清楚,适合子 Agent。
3)需要并行探索的任务
例如写一篇文章前:
- 一个子 Agent 查 docs
- 一个子 Agent 查已有文章风格
- 一个子 Agent 查相关命令输出
最后主 Agent 合并。
4)中间过程很吵的任务
有些任务会产生很多搜索、尝试、失败、重试。
不想污染主对话时,可以交给子 Agent。
5)需要不同模型或 thinking 设置
文档里提到,子 Agent 可以设置 model 和 thinking override。
这意味着你可以:
- 主 Agent 用高质量模型负责决策
- 子 Agent 用更便宜模型做资料整理
- 某些复杂子任务临时提高 thinking
这可以帮助控制成本。
七、什么任务不适合交给子 Agent?
1)一句话能完成的小事
比如:
1 | 帮我把标题改成第 16 课。 |
这种任务直接做就行。
派子 Agent 反而增加复杂度。
2)需要你马上确认的敏感操作
比如:
- 删除文件
- 修改生产配置
- 发送外部消息
- 执行高风险命令
这类任务不适合直接丢给后台 Agent 自己跑。
更好的做法是主 Agent 先说明计划,等你确认。
3)目标很模糊的任务
比如:
1 | 去研究一下这个问题。 |
这对子 Agent 来说太宽泛。
它可能查错方向、跑很久、输出一堆没用内容。
4)强依赖实时对话互动的任务
如果任务需要你频繁回答、确认、补充信息,那不适合后台跑。
主对话里处理更自然。
八、写好 task:子 Agent 成败的关键
sessions_spawn 里最重要的参数是:
1 | task |
它就是你交给子 Agent 的任务说明。
子 Agent 做得好不好,很大程度取决于 task 写得清不清楚。
一个好的 task 至少包含 5 个要素:
- 目标:你要它完成什么
- 范围:只能看哪些资料,或优先看哪里
- 限制:不要做什么
- 输出格式:最后怎么汇报
- 验收标准:什么算完成
比如不好的 task:
1 | 查一下 TTS。 |
更好的 task:
1 | 请阅读 /usr/lib/node_modules/openclaw/docs/tools/tts.md,整理 OpenClaw TTS 的核心机制。重点包括:auto-TTS 默认状态、/tts 常用命令、provider、persona、voice note 输出和安全注意事项。只做资料整理,不要修改文件。最终输出 8 条以内要点,并标出最适合新手记住的 3 条。 |
这个任务就清楚很多。

图:好的子 Agent task 应该包含目标、范围、限制、输出格式和验收标准。任务越清楚,子 Agent 越稳定。
九、context: isolated 是什么?
文档里说,native sub-agents 默认是 isolated。
也就是说,如果你不特别说明,子 Agent 会在干净上下文里启动。
你可以理解成:
它不自动继承当前对话的所有细节,只根据你给的 task 开始工作。
isolated 的好处
- 上下文干净
- token 更省
- 不容易带入主对话噪音
- 更适合独立研究、独立实现、独立整理
isolated 的代价
- task 必须写清楚
- 子 Agent 不知道主对话里没写进 task 的背景
- 如果你省略关键条件,它可能做错
适合 isolated 的任务:
1 | 请阅读指定文档,总结核心概念。 |
或者:
1 | 请检查某个目录下文章标题格式是否统一。 |
这类任务只要说明清楚,就不需要继承整个对话。
十、context: fork 是什么?
fork 则相反。
它会把当前 requester transcript 分支给子 Agent。
你可以理解成:
子 Agent 带着当前对话上下文一起出发。
fork 适合什么时候?
适合这些任务:
- 子 Agent 需要理解刚才长对话里的细节
- 子 Agent 要使用前面工具调用结果
- task 很难完整重述
- 当前上下文里有大量约束和判断
例如你刚和主 Agent 讨论了很久一个 bug,已经贴了日志、错误、分析过程。
这时派子 Agent 去进一步查某个方向,可能适合 fork。
fork 的代价
- token 更高
- 上下文更重
- 可能继承主对话里的噪音
- 更容易把无关信息带进子任务
所以文档里也强调:
Use fork sparingly.
也就是:慎用 fork。
它不是懒得写 task 的替代品。
十一、isolated 和 fork 怎么选?
最简单的判断:
能用清楚 task 说明白,就用 isolated;必须继承当前对话细节,才用 fork。
对新手,我建议默认用 isolated。
因为它更安全、更便宜、更可控。
只有当你发现:
- task 写很长也解释不清
- 子 Agent 必须知道刚才的工具结果
- 子 Agent 必须继承当前讨论背景
才考虑 fork。
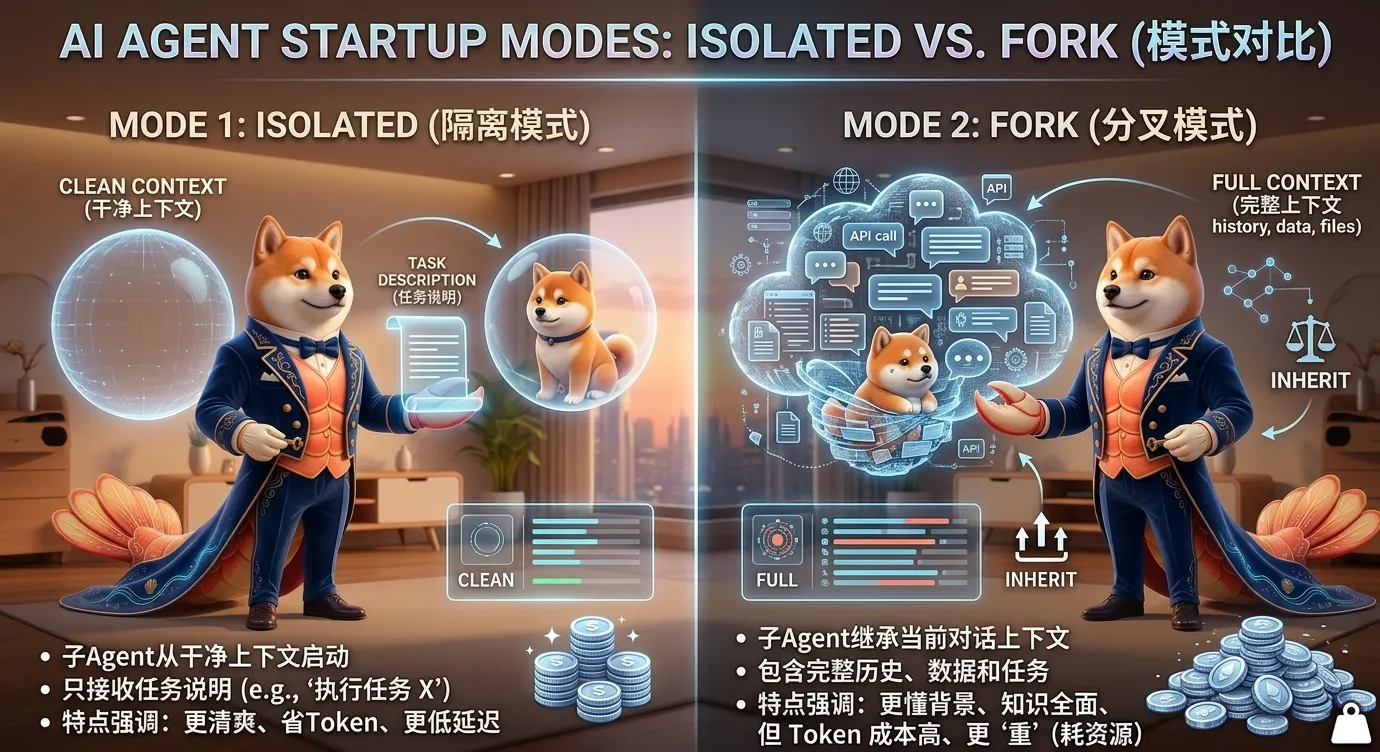
图:isolated 是干净启动,适合清楚独立的任务;fork 会继承当前对话,适合强依赖上下文的任务,但成本更高。
十二、model、thinking 和 runTimeoutSeconds
sessions_spawn 还可以设置一些运行参数。
新手先理解这三个:
modelthinkingrunTimeoutSeconds
model:子 Agent 用哪个模型
默认情况下,子 Agent 会继承调用方模型,除非你配置了 subagents 默认模型,或者在 spawn 时显式指定。
实际使用时,可以这样设计:
- 主 Agent 用更强模型负责最终判断
- 子 Agent 用便宜模型做资料整理
- 关键子任务临时使用强模型
这能平衡质量和成本。
thinking:子 Agent 的思考级别
有些任务简单,不需要高 thinking。
有些任务复杂,比如分析源码、设计方案,可以提高 thinking。
但 thinking 越高,通常也越耗时、越贵。
所以不要默认把所有子 Agent 都开到最高。
runTimeoutSeconds:最长运行时间
这是很实用的安全阀。
如果你担心子 Agent 跑太久,可以设置超时。
比如:
1 | runTimeoutSeconds: 900 |
表示最多跑 15 分钟。
文档里也提到,如果没设置,默认可能是 0,也就是不设超时,具体还会受配置影响。
我建议长任务都给一个合理上限。
十三、sandbox: require 是什么?
sessions_spawn 里还有一个安全相关参数:
1 | sandbox: "require" |
它的意思是:
只有目标子 Agent 能在 sandbox 中运行时,才允许派生。
这适合更谨慎的场景。
比如你要让子 Agent 分析不可信文件、跑命令、查看未知项目。
你可以要求它必须在 sandbox 中运行。
如果无法保证 sandbox,就拒绝派生。
这是一种安全边界。
它不是每个任务都必须用,但对于有执行风险的任务很有价值。
十四、cleanup: keep 和 delete
sessions_spawn 还有 cleanup 选项。
常见有:
keepdelete
keep
保留子 Agent session 一段时间,方便后续查看。
这适合调试和复盘。
delete
完成 announce 后立即归档。
文档里说明,delete 不是彻底抹掉一切,而是 archive,会通过 rename 保留 transcript。
适合不需要长期保留 session 列表的短任务。
新手可以先用默认 keep,等熟悉后再根据任务性质调整。
十五、thread-bound sessions 是什么?
文档里还提到 thread: true。
这属于更进阶的用法。
它允许子 Agent 绑定到聊天线程。
也就是说,后续在那个 thread 里的消息,可以继续路由给同一个子 Agent session。
目前文档里明确提到 Discord 支持 persistent thread-bound subagent sessions。
新手先不用急着用。
你可以先记住:
- 普通后台任务:
mode: "run" - 需要持续线程会话:才考虑
thread: true和mode: "session"
对于 Telegram 直接对话这类场景,先理解普通后台子任务就够了。
十六、一个最小例子:派子 Agent 查文档
假设你要写一篇 TTS 教程。
你可以让主 Agent 派一个子 Agent:
1 | 请派一个子 Agent 阅读 /usr/lib/node_modules/openclaw/docs/tools/tts.md,整理 OpenClaw TTS 的核心机制。要求:只读文档,不修改文件;输出 8 条以内结论;重点覆盖 /tts 命令、auto-TTS、provider、persona、voice note 和安全注意事项。 |
这就是一个好任务。
因为它:
- 目标明确:整理 TTS 核心机制
- 范围明确:指定文档
- 限制明确:只读,不改文件
- 输出明确:8 条以内
- 重点明确:列出要覆盖的主题
主 Agent 派出去后,不需要一直等。
子 Agent 完成后会回传结果。
十七、一个并行例子:两个子 Agent 分工
假设你要写一篇更复杂的文章。
可以这样分工:
子 Agent A:查官方文档
1 | 阅读 OpenClaw docs 里和 subagents / sessions_spawn 相关的文档,整理准确概念和参数。只读,不修改文件。输出 10 条以内要点。 |
子 Agent B:查已有教程风格
1 | 阅读 articles 目录里第 12 到第 15 课,提炼文章结构、语气、配图建议格式。只读,不修改文件。输出写作风格建议。 |
主 Agent 最后把 A 的事实和 B 的风格合起来。
这就是真正的多 Agent 协作。
不过注意:
不要为了并行而并行。
如果一个子 Agent 能做完,就别拆太碎。
十八、子 Agent 的工具权限不是无限的
OpenClaw 对子 Agent 有工具限制。
文档里提到一个重要原则:
子 Agent 默认不拿 session tools。
这意味着普通 leaf 子 Agent 不能随便继续 spawn 更多子 Agent。
这是为了避免递归失控。
如果开启更深的 nesting,例如 maxSpawnDepth >= 2,深度 1 的 orchestrator 才会获得部分编排工具。
而 leaf worker 仍然不能无限继续派生。
所以不要把子 Agent 理解成“复制一个完全无约束的自己”。
它更像是一个受控的后台任务单元。
十九、不要把 channel delivery 参数塞给 sessions_spawn
文档里有一个容易踩的点:
sessions_spawn不接受 channel-delivery params。
也就是说,不要给它传:
targetchanneltothreadIdreplyTotransport
它不是消息发送工具。
它是派生子 Agent 的工具。
子 Agent 要发送消息,可以在自己的任务里通过合适方式做,或者完成后通过 announce 回来。
这点要分清楚。
二十、常见坑
坑 1:把 sessions_spawn 当同步调用
错误理解:
派出去后马上拿最终结果。
正确理解:
sessions_spawn 只负责启动,结果稍后 announce 回来。
坑 2:task 太模糊
比如:
1 | 查一下这个问题。 |
太泛了。
正确做法:
写清目标、范围、限制、输出格式和验收标准。
坑 3:滥用 fork
fork 会带来更多上下文和 token。
如果任务本来可以独立描述,就用 isolated。
坑 4:派太多子 Agent
多 Agent 有成本。
先少量并行,确认方向对,再扩展。
坑 5:忘记设置超时
长任务最好给合理的 runTimeoutSeconds。
避免子 Agent 跑太久。
坑 6:把敏感操作交给后台 Agent 自己做
删除文件、发外部消息、改生产配置这类操作,不适合直接丢给后台子 Agent。
应该让主 Agent 先列计划,等你确认。
坑 7:结果回来后原样转发内部元数据
announce 里的运行统计、sessionKey、transcript path 对用户不一定有用。
主 Agent 应该整理成人话。
二十一、适合新手的 sessions_spawn 提问模板
下面这些句式可以直接复制。
1)派子 Agent 查文档
1 | 请派一个子 Agent 阅读指定文档,整理核心结论。只读,不修改文件。输出 8 条以内要点,完成后回报。 |
2)要求 isolated
1 | 这个任务可以独立完成,请用 isolated 上下文派生子 Agent。task 里写清楚所有必要背景,不要 fork 当前对话。 |
3)要求 fork
1 | 这个任务依赖刚才的对话和工具结果,请用 fork 上下文派生子 Agent,并让它只分析其中一个方向。 |
4)限制子 Agent 不写文件
1 | 请派子 Agent 做只读分析,不要写文件,不要执行破坏性命令,不要发送外部消息。 |
5)控制输出格式
1 | 子 Agent 最终只输出 5 条结论,每条不超过 2 句话,并标明依据来自哪里。 |
6)设置超时意识
1 | 如果派生子 Agent,请给它设置合理超时。超过时间就让它返回已完成的部分总结。 |
7)并行但少量
1 | 最多派 2 个子 Agent:一个查官方文档,一个查已有文章风格。不要继续派生更多子 Agent。 |
这些模板的核心是:
让子 Agent 带着清楚边界出发。

图:安全派生子 Agent 的关键是少量、明确、可控:目标清楚、范围清楚、权限边界清楚、完成后再汇总。
二十二、和第 17 课的关系
第 16 课解决的是:
怎么把子 Agent 派出去。
第 17 课解决的是:
派出去以后怎么管理。
也就是:
- 第 16 课:
sessions_spawn - 第 17 课:
subagents
你可以把它们理解成一套完整流程:
- 主 Agent 判断任务是否适合拆出去
- 用
sessions_spawn派生子 Agent - 子 Agent 独立运行
- 必要时用
subagents list / steer / kill管理 - 子 Agent 完成后 announce 回来
- 主 Agent 汇总成用户可读结果
学会这套流程,多 Agent 才不是“多开几个 AI”,而是有组织的任务协作。
二十三、这一课最值得记住的一句话
如果今天只记一句话,我建议你记这句:
sessions_spawn 不是拿结果的工具,而是派任务的工具。
再补一句使用原则:
任务清楚才派,默认 isolated,必要时 fork,长任务设超时。
二十四、总结
今天这节课,我们讲清楚了 OpenClaw 的 sessions_spawn:
- sessions_spawn 用来派生子 Agent。
- 子 Agent 在自己的 session 中后台运行。
- sessions_spawn 是非阻塞的,启动后不会等最终结果。
- 子 Agent 完成后通过 announce 把结果回传。
- 适合子 Agent 的任务通常是耗时、独立、可并行或需要隔离上下文的任务。
- 不适合把一句话小事、敏感操作、模糊任务交给子 Agent。
- task 写得越清楚,子 Agent 越稳定。
- isolated 是默认,适合独立任务;fork 适合强依赖当前上下文的任务。
- model、thinking、runTimeoutSeconds 可以帮助控制质量、成本和时间。
- sessions_spawn 负责派出,subagents 负责管理。
从这一课开始,你就真正进入 OpenClaw 的多 Agent 工作方式了。
它不是让一个 AI 无限变强,而是让多个受控的 Agent 在清楚边界里协作。
下一课预告
下一课就是:
第 17 课:subagents 管理——监控、干预、终止
也就是:
- 怎么查看子 Agent 状态
- 什么时候该 steer 干预
- 什么时候该 kill 终止
- 为什么不要轮询等待
- 子 Agent 完成后怎么整理结果
🦞 本文由八条撰写,持续更新中。