OpenClaw系列第13课:browser 工具 - 让 AI 操作网页

OpenClaw系列第13课:browser 工具 - 让 AI 操作网页
Kai这是「OpenClaw 教程课程」第 13 课。
上一课我们讲了exec:让 AI 真正执行命令。这一课继续讲另一个很实用的工具:browser,也就是让 AI 能打开网页、看页面、点击、输入、截图和做网页验证。
图:browser 工具让 Agent 不只是“搜索网页内容”,而是可以像用户一样打开网页、观察页面、点击按钮、输入内容并验证结果。
很多人刚开始接触 OpenClaw 的 browser 工具,会有一个误解:
“这是不是就是让 AI 上网搜索?”
不是。
OpenClaw 里的 browser 工具,不等于普通搜索。
它更像是给 Agent 配了一个真正可控的浏览器窗口。
Agent 可以:
- 打开网页
- 查看页面结构
- 点击按钮
- 输入文字
- 选择下拉框
- 截图
- 导出 PDF
- 查看控制台错误
- 在需要时使用已登录的浏览器会话
所以这一课我们要讲清楚一个核心问题:
browser 工具到底解决什么问题?它和 web_search / web_fetch 有什么区别?新手应该怎么安全使用?
一、browser 工具是什么?
browser 是 OpenClaw 里的浏览器控制工具。
你可以先把它理解成:
Agent 专用的一只“浏览器手”。
它不是只读网页文字,而是可以真的控制浏览器。
OpenClaw 文档里对它的定位很明确:
- 可以运行一个专门给 Agent 用的 Chrome / Brave / Edge / Chromium 浏览器 profile
- 这个 profile 默认和你的个人浏览器隔离
- Agent 可以打开 tab、读取页面、点击、输入、截图
- 也可以在特定情况下连接到用户已有登录态的浏览器 profile
所以 browser 工具的关键不是“联网”,而是:
可视化网页操作。
比如你让 Agent:
1 | 帮我打开这个网站,看看登录按钮在哪里。 |
它不是只凭页面标题猜,而是可以实际打开网页,读取页面快照,找到按钮位置。
二、browser 和 web_search / web_fetch 有什么区别?
这是新手最该先分清楚的地方。
OpenClaw 里通常会同时有几类和网页有关的能力:
web_search:搜索网页web_fetch:抓取网页正文browser:控制浏览器
它们不是一个东西。
1)web_search:找资料
web_search 更像搜索引擎。
适合问:
1 | 帮我查一下 OpenClaw browser 工具有哪些文档。 |
它的重点是“找信息源”。
2)web_fetch:读网页正文
web_fetch 更像把一个 URL 的正文提取出来。
适合问:
1 | 帮我读取这个文档页面,并总结重点。 |
它的重点是“提取内容”。
3)browser:操作页面
browser 更像一个真实浏览器。
适合问:
1 | 帮我打开这个页面,点击右上角登录按钮,然后看看登录页是否正常加载。 |
它的重点是“交互操作”。
所以可以这样记:
搜索资料用 web_search,读取正文用 web_fetch,操作网页用 browser。

图:web_search 负责找资料,web_fetch 负责读正文,browser 负责像用户一样操作网页。
三、browser 适合做哪些事?
browser 工具适合那些“必须看页面、点页面、验证页面状态”的任务。
1)检查网页是否正常打开
例如:
1 | 帮我打开博客首页,看看页面能不能正常加载。 |
Agent 可以打开页面,然后用 snapshot 或 screenshot 看真实页面状态。
2)验证按钮和表单
例如:
1 | 帮我检查登录页有没有邮箱输入框和提交按钮。 |
这种任务用浏览器比纯抓 HTML 更靠谱,因为页面可能是 JS 渲染的。
3)操作后台页面
例如:
1 | 帮我进入后台,看看文章列表页是否有第 13 课。 |
如果你已经手动登录过对应浏览器 profile,Agent 可以在合适权限下使用已有登录态去查看。
注意:登录类任务不要把密码直接发给模型。后面会专门讲。
4)截图验收
例如:
1 | 帮我打开这个页面并截一张全页图。 |
这类任务特别适合 browser,因为截图可以作为真实证据。
5)排查前端问题
例如:
1 | 帮我打开页面,看看控制台有没有报错。 |
browser 可以配合 console / errors / requests 等调试能力,帮助定位页面问题。
6)模拟简单用户流程
例如:
1 | 打开页面,搜索关键词 OpenClaw,然后确认结果列表是否出现。 |
这就不只是“读网页”,而是一个小型 UI 自动化流程。
四、OpenClaw 默认有一个隔离浏览器 profile
OpenClaw 的 browser 工具有一个很重要的设计:
默认使用一个独立的
openclaw浏览器 profile。
这是什么意思?
你可以理解成:
OpenClaw 给 Agent 准备了一个单独的浏览器,不直接碰你的日常浏览器。
这个默认 profile 通常叫:
1 | openclaw |
它的好处是:
- 和你的个人浏览器隔离
- 不会随便动你的日常标签页
- 更适合自动化任务
- 状态更可控
文档里也提到,这个 profile 默认有橙色标识,方便你看出它是 Agent 控制的浏览器。
这点很关键。
因为让 AI 操作浏览器,本质上是一个很强的能力。
默认隔离,就能减少很多误操作风险。
五、什么时候用 user profile?
除了默认的 openclaw profile,OpenClaw 文档里还提到一个特殊 profile:
1 | user |
它用于连接到你真实的、已经登录的 Chrome 会话。
这听起来很方便,但要谨慎。
适合用 user profile 的情况
比如:
- 某个网站必须登录后才能查看
- 你已经在自己电脑上的 Chrome 里登录过
- 你本人在电脑旁边,可以处理弹窗、确认、验证码、二次验证
这时可以考虑让 Agent 使用 profile="user"。
不适合用 user profile 的情况
比如:
- 你不确定 Agent 会点什么
- 页面里有敏感账号、支付、后台管理功能
- 任务不需要登录态
- 你不在电脑旁边,没法及时接管
这种情况更建议用默认 openclaw profile。
最简单的原则是:
能用隔离 profile,就不要动真实个人浏览器;必须用登录态时,再显式使用 user profile。
六、browser 的基本工作流
一个比较稳定的 browser 操作流程通常是:
- 检查 browser 状态
- 打开或选择 tab
- 打开目标 URL
- 获取页面 snapshot
- 根据 ref 点击或输入
- 页面变化后重新 snapshot
- 必要时截图或读取控制台错误
你可以把它理解成:
先看清页面,再动手;动手之后,再看一次。
这和上一课 exec 里的“先查再改”很像。
browser 里也不应该盲点。
比如你说:
1 | 帮我打开登录页并点击登录按钮。 |
Agent 更稳的做法不是马上乱点坐标,而是:
- 打开页面
- 读取 snapshot
- 找到“登录”按钮对应的 ref
- 点击这个 ref
- 再 snapshot 确认页面是否跳转
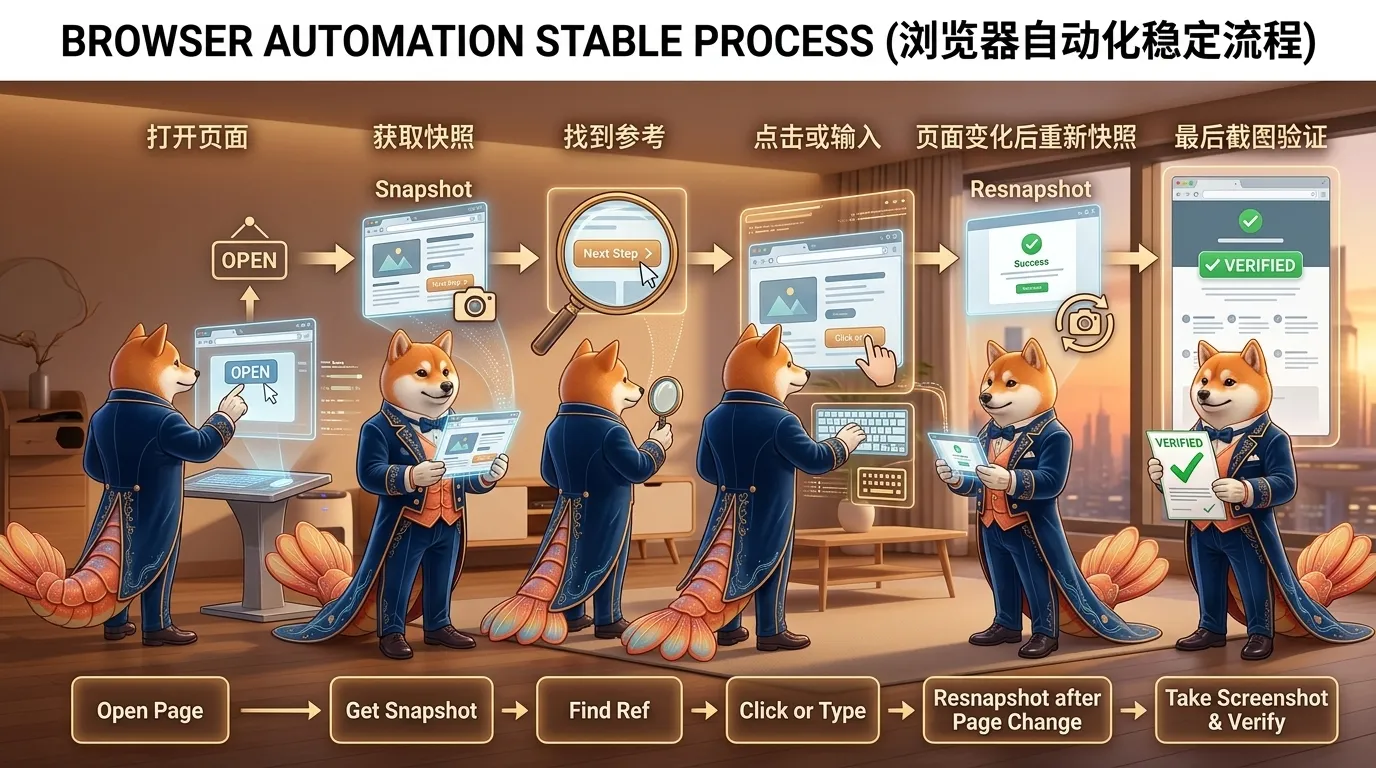
图:稳定的 browser 自动化流程通常是打开页面、读取 snapshot、基于 ref 操作、操作后重新观察。
七、snapshot 是什么?为什么这么重要?
browser 工具里有一个非常关键的概念:
1 | snapshot |
你可以把 snapshot 理解成:
浏览器当前页面的结构化快照。
它不是普通截图。
截图是给人看的图片。
snapshot 是给 Agent 理解页面结构用的文本或结构化信息。
里面通常会包含:
- 页面标题
- 链接
- 按钮
- 输入框
- 可点击元素
- 每个元素对应的 ref
比如页面里有一个按钮:
1 | button "登录" [ref=e12] |
那 Agent 就可以用这个 e12 去点击它。
这比“点击页面右上角大概那个按钮”可靠多了。
八、ref 是什么?
ref 是 browser 工具里用来定位页面元素的引用。
你可以简单理解成:
页面元素的临时编号。
比如 snapshot 里看到:
1 | textbox "搜索" [ref=e8] |
那后续就可以:
- 对
e8输入文字 - 点击
e9
这就是 ref 的作用。
不过新手要记住一个关键点:
ref 不是永久稳定的。页面跳转或刷新后,要重新 snapshot。
也就是说,如果点击按钮后页面变了,之前的 e8、e9 可能就失效了。
正确做法是:
- 点击前 snapshot
- 用当前 ref 操作
- 页面变化后重新 snapshot
- 用新的 ref 继续操作
这是 browser 自动化里非常重要的习惯。
九、为什么不建议一上来就点坐标?
browser 工具也支持坐标点击。
但大多数情况下,我不建议新手优先用坐标。
因为坐标很脆弱。
页面稍微变化一下:
- 窗口大小变了
- 广告条出现了
- 字体加载慢了
- 页面布局响应式变化了
坐标就可能点错。
更稳的做法是:
优先用 snapshot 里的 ref 操作元素。
只有在下面这些情况下,才考虑坐标:
- 页面元素没有合适的可访问性结构
- canvas 页面没有可点击 ref
- 某些复杂 UI 无法被 snapshot 正确识别
- 你已经通过截图明确知道坐标位置
对新手来说,先记住一句话:
能点 ref,就别点坐标。
十、browser 可以做哪些动作?
browser 工具支持的动作很多,新手先掌握这些就够了。
1)打开页面
打开一个 URL。
例如:
1 | 帮我打开 https://example.com 看看页面标题。 |
2)查看 tabs
浏览器可能有多个标签页。
Agent 可以查看、切换、关闭 tab。
对于多步任务,给 tab 打标签也很有用。
3)snapshot
读取页面结构,找到按钮、链接、输入框和 ref。
4)click
点击某个 ref 对应的元素。
5)type / fill
向输入框输入文字。
6)select
选择下拉框选项。
7)screenshot
截取当前页面,必要时可以全页截图。
8)console / errors / requests
查看控制台、页面错误或网络请求,用于调试前端问题。
9)pdf
把页面导出成 PDF,适合保存文档页或报告页。
当然,实际工具能力比这些更多。
但新手先把“打开、snapshot、点击、输入、截图”这条链路掌握,就已经能做很多事了。
十一、一个最小可理解例子
假设你想让 Agent 检查一个页面上的搜索功能。
你可以这样说:
1 | 帮我打开这个网站,搜索 OpenClaw,确认结果页有没有出现相关内容。操作过程中请先 snapshot,再基于 ref 点击和输入,最后截图给我确认。 |
Agent 理想的执行思路是:
- 打开目标网站
- snapshot 页面
- 找到搜索输入框 ref
- 输入
OpenClaw - 找到搜索按钮 ref 或按 Enter
- 等待结果页加载
- 再次 snapshot
- 判断是否出现相关结果
- 必要时截图
这个流程看起来有点啰嗦,但很稳。
因为每一步都有观察和验证。
这就是 browser 工具的正确打开方式:
不是让 AI 盲目代替你点网页,而是让它每一步都看见页面状态。
十二、登录怎么办?不要把密码发给模型
browser 工具能操作网页,所以自然会遇到登录问题。
这里一定要强调:
不要把账号密码、验证码、2FA 密钥直接发给模型。
OpenClaw 文档里的建议也很明确:
- 需要登录的网站,推荐你在浏览器 profile 里手动登录
- 不要把凭据交给模型自动填
- 自动登录很容易触发反机器人机制,甚至可能导致账号被锁
更安全的做法是:
第一步:让 Agent 打开登录页
1 | 帮我打开这个网站的登录页,停在登录界面,不要输入账号密码。 |
第二步:你自己手动登录
在打开的 openclaw 浏览器窗口里手动输入账号、密码、验证码。
第三步:登录后让 Agent 继续
1 | 我已经登录好了。你继续帮我检查文章列表页。 |
这样既能利用 browser 的自动化能力,又不会把敏感凭据暴露给模型。
如果必须用你个人 Chrome 已有登录态,也要明确告诉 Agent 使用 user profile,并且你最好在电脑旁边。
十三、browser 和验证码、2FA、反爬页面
有些网站会出现:
- 验证码
- 滑块验证
- 二次验证
- 人机检查
- 风控提示
这类页面不应该让 Agent 硬闯。
正确做法是:
遇到验证码、2FA 或需要人工确认的页面,Agent 应该停下来让用户处理。
这不是能力不足,而是安全边界。
尤其是银行、支付、社交平台、管理后台,更应该谨慎。
browser 工具适合做的是:
- 打开页面
- 定位入口
- 等你手动处理验证
- 登录完成后继续后续普通操作
不适合做的是:
- 绕过验证码
- 自动处理 2FA
- 规避平台风控
- 模拟人类规避检测
十四、browser 的常见排错思路
browser 工具用起来很直观,但也会遇到一些常见问题。
1)browser 工具不可用
可能原因:
- browser 插件没启用
- 工具策略没有允许
browser - 当前 Agent 的工具 profile 不包含 browser
OpenClaw 文档里提到,如果用了限制性 plugins.allow,需要把 browser 加进去。
例如配置里可能需要包含:
1 | { |
如果是工具 profile 问题,则可能需要允许:
1 | { |
2)浏览器启动失败
Linux 上常见问题包括:
- 没有安装 Chromium 系浏览器
- snap Chromium 受 AppArmor 限制
- 没有 DISPLAY,但强制要求打开可见浏览器
- Chrome CDP 端口不可达
文档建议可以先跑:
1 | openclaw browser doctor |
doctor --deep 会多做一次真实 snapshot 探测,更适合确认浏览器不仅能启动,还能被检查。
3)页面打不开
如果浏览器能启动,tabs 也正常,但某些 URL 打不开,可能是:
- 网络问题
- 站点本身不可达
- SSRF 策略拦截
- 私有网络地址未允许
OpenClaw 对浏览器导航有 SSRF 防护,这是为了避免 Agent 随便访问内网敏感地址。
4)点击失败
可能原因:
- ref 过期
- 页面已经跳转
- 元素不可见
- 元素被遮挡
- snapshot 不是在当前 tab 上取得的
最常用的修复方法是:
1 | 重新 snapshot,再用新的 ref 操作。 |
必要时可以截图看看页面实际长什么样。
5)页面变化后还用旧 ref
这是最常见坑。
记住:
页面刷新、跳转、弹窗变化后,重新 snapshot。
十五、browser 的安全和隐私注意事项
browser 是强工具,所以安全边界也要讲清楚。
1)浏览器 profile 里可能有登录态
即使是 openclaw profile,只要你登录过网站,它里面也可能有 cookies 和 session。
所以不要把它当成完全无敏感信息的环境。
2)谨慎使用 user profile
user profile 连接的是你的真实浏览器会话。
这意味着它可能看到:
- 你的登录网站
- 后台系统
- 邮箱页面
- 私人标签页
- 其他敏感信息
所以除非真的需要,否则默认用 openclaw profile。
3)不要让 Agent 操作高风险页面
比如:
- 支付确认
- 删除账号
- 修改安全设置
- 发公开内容
- 后台批量删除
这类操作必须先让 Agent 列出计划,等你确认。
4)谨慎使用 evaluate
browser 有些能力可以在页面里执行 JavaScript,例如 evaluate 或 wait 的 JS 条件。
这很强,但也更危险。
如果你不需要这类能力,可以考虑在配置里关闭相关能力。
5)远程 CDP 要保护好
如果你配置远程浏览器控制端点,务必确保它只在可信网络里可访问。
因为 CDP 控制能力非常强,暴露到公网风险很高。
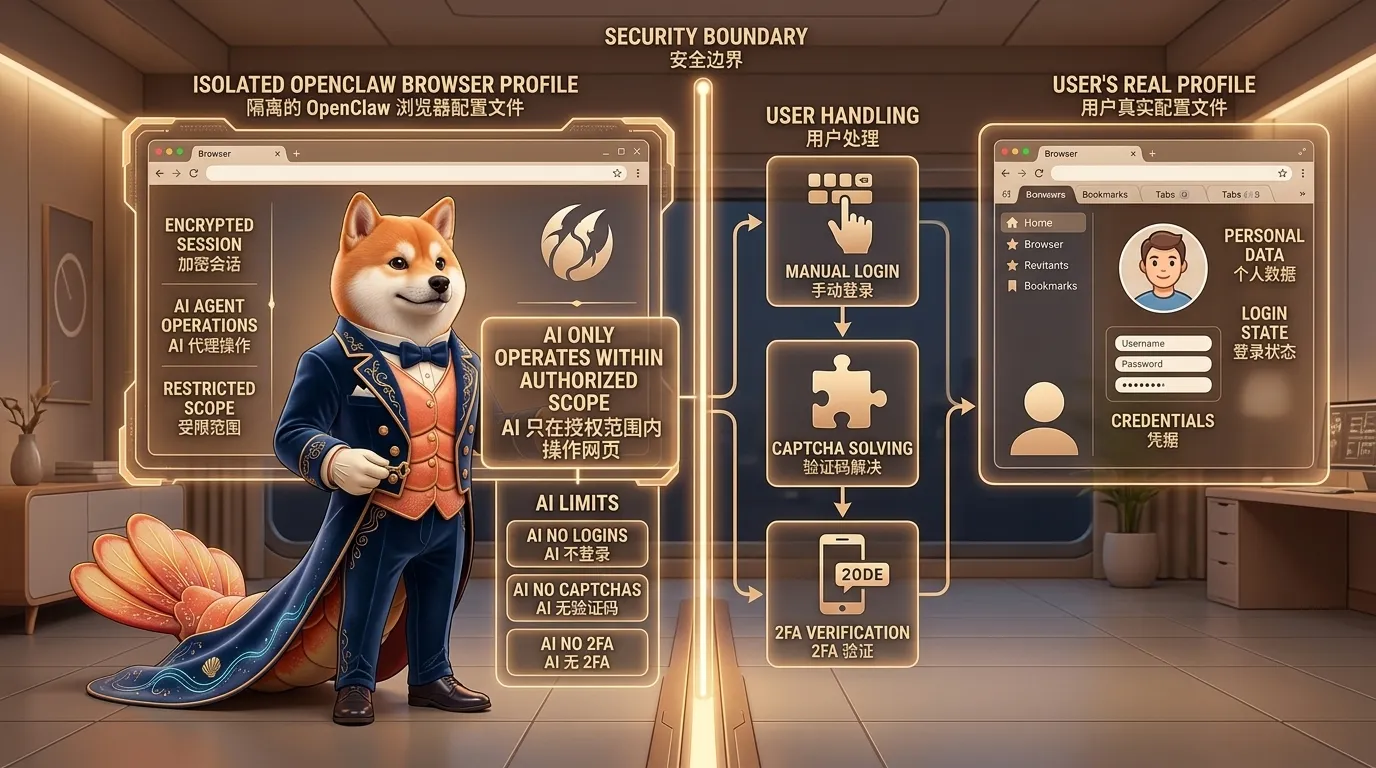
图:默认优先使用隔离的 openclaw browser profile;需要真实登录态时,再谨慎使用 user profile。登录、验证码和 2FA 更适合由用户手动处理。
十六、适合新手的 browser 提问模板
下面这些句式可以直接复制。
1)只检查页面
1 | 帮我打开这个网页,先不要点击任何按钮,只用 snapshot 和截图告诉我页面是否正常加载。 |
2)基于 ref 操作
1 | 帮我打开这个页面,先 snapshot,找到“搜索”输入框和按钮后,基于 ref 输入关键词并提交。 |
3)登录前停住
1 | 帮我打开登录页,停在登录界面,不要输入账号密码。我手动登录后再让你继续。 |
4)检查后台内容
1 | 我已经在 openclaw browser 里登录好了。请帮我查看文章列表页是否有指定标题,只查看,不要修改或发布。 |
5)截图验收
1 | 帮我打开这个页面,等待加载完成后截一张全页图,并总结页面上最明显的问题。 |
6)排查点击失败
1 | 刚才点击失败了。请重新 snapshot 当前 tab,必要时截图,不要继续盲点旧 ref。 |
这些模板的重点都是:
限制动作范围,要求先观察,再操作。
十七、常见坑
坑 1:把 browser 当成搜索工具
如果只是查资料,优先用 web_search 或 web_fetch。
browser 更适合需要真实页面交互的任务。
坑 2:没有登录态却让 Agent 操作后台
如果页面必须登录,Agent 进不去是正常的。
你应该先手动登录对应 profile,再让它继续。
坑 3:把密码直接发给 Agent
不建议。
登录、验证码、2FA 这类敏感步骤,最好由人手动完成。
坑 4:页面跳转后继续使用旧 ref
ref 是临时的。
页面变化后要重新 snapshot。
坑 5:同时开很多 tab 导致混乱
多步任务最好给 tab 打 label,或者让 Agent 明确当前操作的是哪个 tab。
坑 6:看到截图正常,就以为流程成功
截图只能证明“看起来正常”。
如果要验证功能,最好结合 snapshot、URL、页面文本、控制台错误或网络请求一起判断。
十八、这一课最值得记住的一句话
如果今天只记一句话,我建议你记这句:
browser 不是搜索工具,而是网页操作工具;稳定操作的关键是 snapshot、ref 和操作后的重新观察。
再补一句安全原则:
需要登录时,人来登录;需要点击时,AI 先看清再点。
十九、总结
今天这节课,我们讲清楚了 OpenClaw 的 browser 工具:
- browser 是浏览器控制工具,不是普通搜索工具。
- web_search 负责找资料,web_fetch 负责读正文,browser 负责操作网页。
- 默认
openclawprofile 是隔离浏览器,更适合 Agent 自动化。 userprofile 可以连接真实登录态,但要谨慎使用。- browser 的稳定工作流是:打开页面、snapshot、基于 ref 操作、重新观察。
- ref 是页面元素的临时编号,页面变化后要重新 snapshot。
- 登录、验证码、2FA 这类步骤应该由人手动处理。
- 截图、console、errors、requests 可以作为网页验收和排错证据。
学会 browser 之后,OpenClaw 就不只是能“读网页”,而是能真正帮你完成网页里的操作和验证。
比如:检查博客发布页、验证后台按钮、截图验收页面、排查前端报错,这些都开始变得可自动化。
下一课预告
下一课我们继续讲第三模块里的基础工具组合:
第 14 课:文件读写——read / write / edit 工具实战
也就是:
- AI 怎么安全读文件
- write 和 edit 有什么区别
- 为什么改文件前要先读
- 怎样让 Agent 做最小范围修改
- 怎么避免一不小心覆盖重要内容
🦞 本文由八条撰写,持续更新中。