OpenClaw系列第15课:TTS 语音 - 让 OpenClaw 开口说话

OpenClaw系列第15课:TTS 语音 - 让 OpenClaw 开口说话
Kai这是「OpenClaw 教程课程」第 15 课。
这一课是第三模块「工具与技能」的最后一篇。前面我们讲了 Skills、exec、browser、read / write / edit。今天讲一个很有“陪伴感”的能力:TTS 语音。
图:TTS 让 OpenClaw 不只会用文字回复,也可以把回答转换成语音,通过语音消息或音频附件发送给用户。
很多人第一次看到 OpenClaw 的 TTS,会觉得它只是一个“小功能”:
把文字读出来而已。
但实际用起来,你会发现它改变的是交互方式。
文字回复适合仔细阅读。
语音回复适合快速听、移动中听、做事时听。
比如:
- 早上让 Agent 语音播报今日事项
- 跑完任务后发一段语音结果
- 开车或做饭时听简短总结
- 把长文章摘要转成语音
- 让某个 Agent 用固定声音说话
所以 TTS 的价值不是“炫技”,而是:
让 OpenClaw 从文字助手,变成可以开口说话的助手。
一、TTS 是什么?
TTS 是 Text-to-Speech 的缩写。
中文可以理解成:
文字转语音。
在 OpenClaw 里,TTS 的作用是把 Agent 的文字内容转换成音频,然后通过聊天渠道发送出去。
这个音频可能是:
- Telegram 里的语音消息
- WhatsApp 里的 voice note
- Matrix / Feishu 里的语音消息
- 其他渠道里的普通音频附件
所以 TTS 不是让模型“换一种语气写字”。
它是真正生成音频文件。
二、TTS 和普通文字回复有什么区别?
普通文字回复是给你看的。
TTS 是给你听的。
这会带来几个明显区别。
1)语音更适合短内容
文字可以很长。
你可以慢慢看、跳读、复制、搜索。
但语音一旦太长,就容易变成负担。
所以 TTS 更适合:
- 简短总结
- 结果播报
- 提醒通知
- 状态更新
- 一段温和解释
不太适合:
- 大段代码
- 长配置
- 多层列表
- 复杂表格
- 需要复制的命令
2)语音更有打扰感
文字消息你可以晚点看。
语音消息会更像“有人在说话”。
所以 TTS 需要更克制。
特别是在群聊、深夜、工作频道里,自动语音很容易打扰人。
3)语音更适合“结论先行”
文字可以展开论证。
语音最好先说结果。
例如:
1 | 构建成功了。耗时 42 秒,没有发现错误。 |
比:
1 | 我先检查了 package.json,然后运行了 npm run build,接着观察到…… |
更适合语音场景。
所以 TTS 不是简单把原文照读。
更好的语音回复,通常要更短、更口语、更聚焦。
三、OpenClaw 的 TTS 能做什么?
根据 OpenClaw 文档,TTS 可以把 outbound replies 转换成音频,并根据不同渠道用合适方式发送。
简单说,它可以做到:
- 把指定文本转成语音
- 把最新一条回复转成语音
- 开启自动语音回复
- 为不同 provider 选择不同声音
- 为不同 Agent 配不同声音或 persona
- 在支持的渠道里发送原生 voice note
- 在其他渠道里发送音频附件
- 长回复必要时先总结再转语音
文档里提到,OpenClaw 支持多种 speech provider,例如:
- OpenAI
- ElevenLabs
- Azure Speech
- Google Gemini
- Microsoft
- MiniMax
- Volcengine
- xAI
- Local CLI
- 以及其他语音提供方
你不需要一开始就全部理解。
新手只要先知道:
TTS = 文本内容 + 语音 provider + 输出渠道。
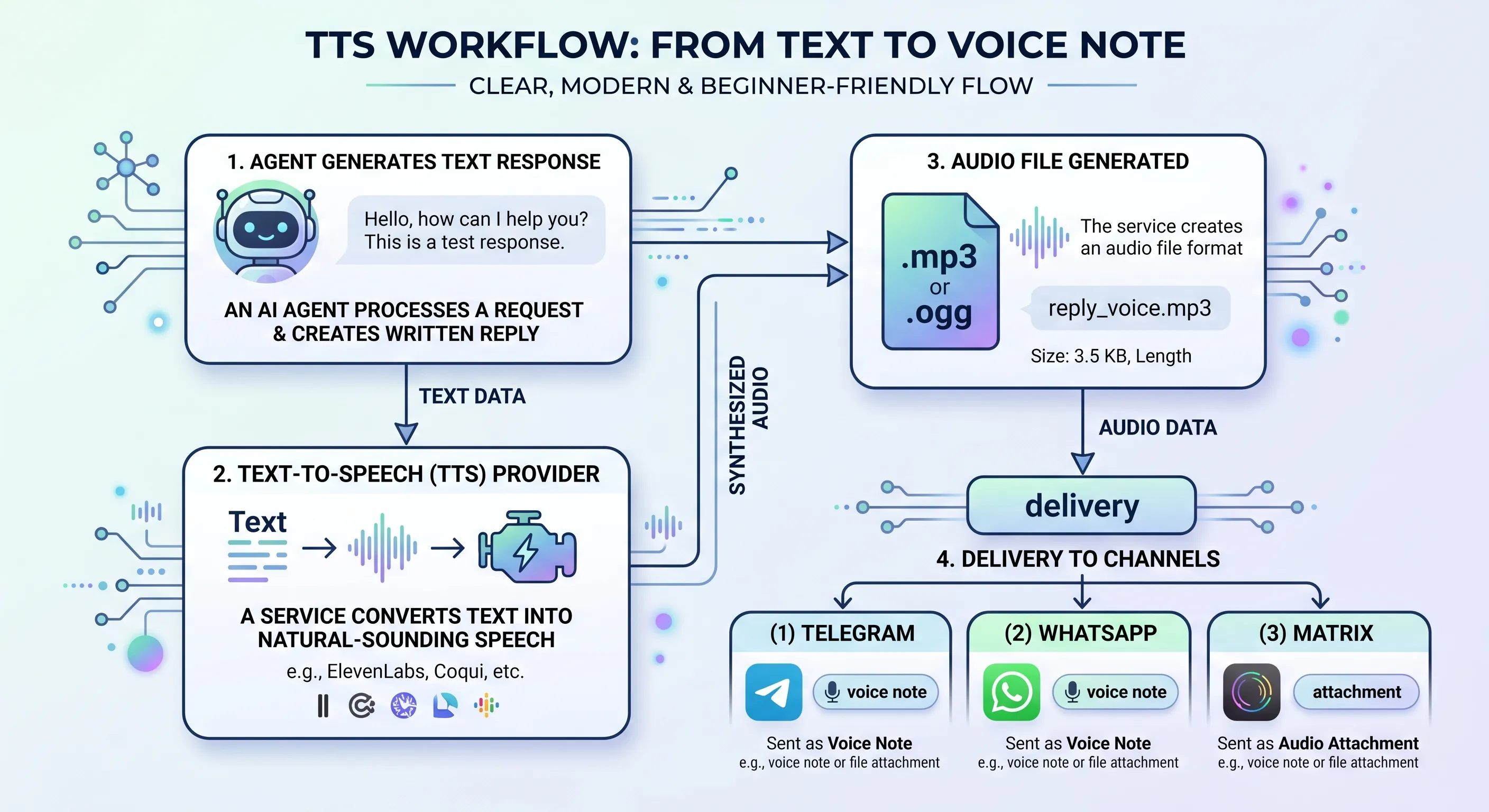
图:TTS 的基本流程是 Agent 生成文字,OpenClaw 选择语音 provider 合成音频,再按渠道能力发送为语音消息或音频附件。
四、TTS 默认不是自动开启的
这一点很重要。
OpenClaw 文档里明确说:
Auto-TTS is off by default.
也就是说,默认情况下,普通聊天还是文字回复。
TTS 不会突然把所有回答都变成语音。
只有在下面几类情况下才会触发:
- 用户明确要求音频
- 使用
/tts命令 - 配置了自动 TTS
- 使用允许的 TTS directive
- Agent 调用
tts工具进行一次性语音生成
这点设计是合理的。
因为语音回复比文字更容易打扰用户。
所以默认关闭,按需开启,才是更稳的方式。
五、最快测试:/tts audio
如果你只是想试一下 TTS 能不能用,最简单的是一次性语音命令。
文档里给的命令是:
1 | /tts audio Hello from OpenClaw |
中文也可以类似这样:
1 | /tts audio 你好,这是一条来自 OpenClaw 的语音测试。 |
这条命令的特点是:
- 只生成这一次音频
- 不会开启长期自动语音
- 适合测试 provider 是否可用
这对新手很友好。
你不用一开始就改配置、开自动,只要先测试一条。
六、查看状态:/tts status
配置或测试 TTS 时,另一个很有用的命令是:
1 | /tts status |
它会显示当前 TTS 状态。
根据文档,状态信息里可能包括:
- 当前是否启用 TTS
- 当前 provider
- 当前 voice / model
- 最近一次尝试是否成功
- fallback 诊断
- 每个 provider 尝试的结果和耗时
这非常适合排错。
比如你发现语音没有发出来,先不要乱改配置。
更好的第一步是:
1 | /tts status |
看看是不是 provider 没配置、API key 缺失、fallback 失败,或者当前模式根本没开启。
七、常用 /tts 命令
OpenClaw 的 TTS 有一组 slash commands。
新手先记这些就够了:
1 | /tts status |
我们逐个解释。
/tts audio <text>
生成一次性语音。
不改变长期设置。
适合测试。
/tts on
开启本机本地偏好的自动 TTS。
文档里说它会把 local TTS preference 写成 always。
简单理解:
后续回复更可能自动变成语音。
/tts off
关闭本地自动 TTS 偏好。
这是很重要的“刹车”。
如果你觉得语音太吵,可以直接关掉。
/tts latest
把当前会话里最新一条 assistant 回复再转成语音发送一次。
这很实用。
比如 Agent 刚发了一段总结,你觉得想听,就可以:
1 | /tts latest |
/tts provider <id>
切换本地偏好的语音 provider。
例如:
1 | /tts provider openai |
或者:
1 | /tts provider elevenlabs |
具体可用 provider 要看你的配置和 API key。
/tts persona <id>
切换当前语音 persona。
persona 可以理解成“稳定的声音身份”。
后面单独讲。
/tts chat on|off|default
这是会话级别的自动 TTS 控制。
比如你只想让当前聊天开语音,可以用:
1 | /tts chat on |
如果当前聊天太吵,可以:
1 | /tts chat off |
八、配置自动 TTS:messages.tts.auto
如果你想长期启用 TTS,需要配置 messages.tts。
文档里的基础示例类似这样:
1 | { |
这里最重要的是:
1 | auto: "always" |
它表示自动 TTS 总是开启。
不过我不建议新手一上来就全局 always。
更稳的方式是:
- 先用
/tts audio测试 - 再用
/tts chat on在某个会话里试 - 确认不打扰后,再考虑全局配置
配置是长期行为,尤其语音会打扰人。
所以不要为了测试,直接把所有 Agent、所有渠道都变成语音回复。
九、provider:谁来合成语音?
TTS provider 就是实际生成声音的服务。
你可以把它理解成:
语音引擎。
不同 provider 的区别包括:
- 声音质量
- 支持语言
- 支持的声音数量
- 是否需要 API key
- 是否支持 voice note 格式
- 是否支持 persona prompt
- 价格和延迟
- 稳定性
OpenClaw 文档里列了很多 provider。
对新手来说,可以先这么选:
想要可靠 hosted provider
可以考虑:
- OpenAI
- ElevenLabs
想要无 API key 先试试
可以考虑:
- Microsoft
- Local CLI
不过文档也提醒:Microsoft provider 使用的是 Microsoft Edge 的在线 neural TTS 服务,属于 best-effort,没有公开 SLA 或 quota。
也就是说:
它适合试用,不适合当成强 SLA 的生产依赖。
想用本地命令合成
可以用 Local CLI。
例如 macOS 上的 say,或你自己安装的本地 TTS 命令。
Local CLI 的好处是可控。
但前提是你本机真的有可用命令,而且配置正确。
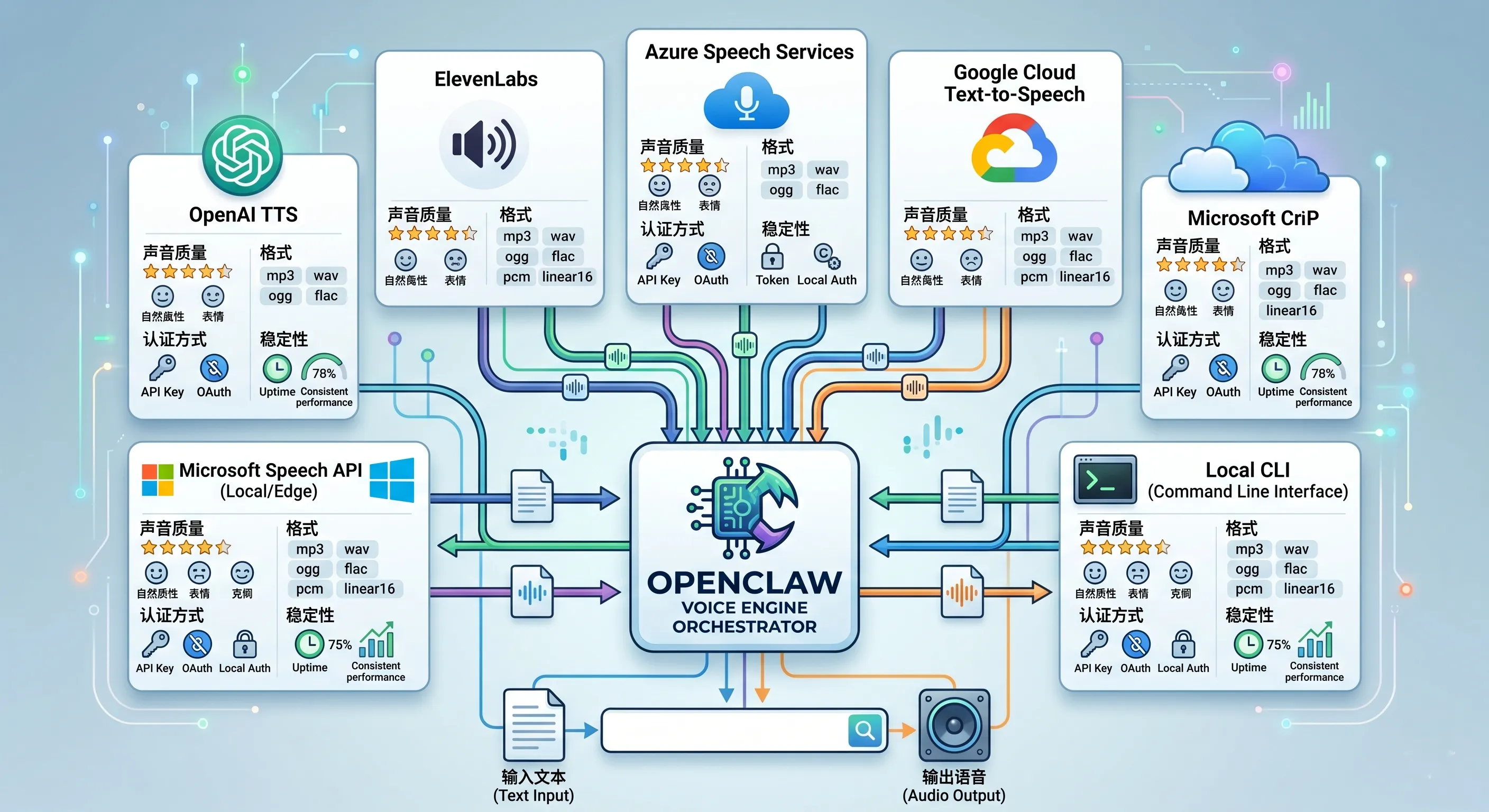
图:TTS provider 是实际合成语音的引擎。不同 provider 在声音质量、认证方式、格式支持和稳定性上会有差异。
十、persona:稳定的“声音身份”
OpenClaw 的 TTS 里有一个很有意思的概念:
1 | persona |
你可以把它理解成:
一个稳定的说话身份。
它不只是声音 ID。
一个 persona 可以包含:
- label:名字
- description:描述
- provider:优先使用哪个 provider
- voice / voiceId:声音
- model:模型
- prompt:说话风格
- pacing:语速节奏
- accent:口音
- constraints:约束
比如你可以有:
narrator:沉稳旁白音assistant:清晰助理音teacher:温和教学音alert:短促提醒音
这样不同 Agent 可以有不同声音。
例如教程 Agent 用温和教学音,告警 Agent 用短促清晰音。
这会让多 Agent 系统更容易区分。
十一、per-agent voice:不同 Agent 用不同声音
OpenClaw 支持给某个 Agent 设置自己的 TTS 配置。
文档里提到可以用:
1 | agents.list[].tts |
也就是说,某个 Agent 可以覆盖全局 messages.tts 设置。
这很适合多 Agent 场景。
比如:
- 教程 Agent:声音温和,适合讲解
- 运维 Agent:声音短促,适合告警
- 阅读 Agent:声音稳定,适合长文朗读
- 家庭助手:声音更自然,适合日常提醒
这也是 TTS 真正有意思的地方。
它不只是“发一段音频”。
它可以让不同 Agent 有不同的听感身份。
十二、voice note 和音频附件有什么区别?
OpenClaw 会根据渠道能力决定怎么发送音频。
文档里提到:
- Feishu、Matrix、Telegram、WhatsApp 支持语音消息风格
- 其他渠道通常发送普通音频附件
- Telegram / WhatsApp 这类渠道更适合 voice note
- 某些情况下会把音频转码成 Ogg/Opus
你可以简单理解:
voice note
更像聊天软件里的“语音消息”。
特点是:
- 通常显示成语音气泡
- 更适合短语音
- 在手机上体验好
audio attachment
更像一个音频文件。
特点是:
- 更通用
- 适合不支持 voice note 的渠道
- 可能显示为文件附件
所以不是所有地方都会显示成同一种语音样式。
OpenClaw 会尽量按渠道能力选择合适输出。
十三、自动 TTS 的跳过规则
自动 TTS 并不是所有回复都转语音。
文档里提到,开启 auto-TTS 时,OpenClaw 会跳过一些情况:
- 回复里已经有媒体或
MEDIA:指令 - 回复太短,比如少于 10 个字符
- 回复超过长度限制且无法总结
- 长回复 summary 关闭或 summary model 不可用
这很合理。
比如一个回复只有:
1 | 好的 |
没必要专门生成语音。
再比如一个回复已经带图片或文件了,也没必要自动再加一段音频。
这说明 TTS 是有节制地触发,而不是盲目读出所有东西。
十四、长回复:先总结再转语音
语音最怕太长。
OpenClaw 文档里提到,如果回复超过限制,且 summary 开启,它可以先用 summary model 总结,再把总结转成语音。
这非常重要。
因为一篇长教程如果直接读出来,可能要十几分钟。
但语音通知更适合这样:
1 | 第 15 课已经写完,主要讲 TTS 的启用方式、provider、persona、voice note 和安全使用建议。 |
这就够了。
所以我建议:
语音默认说摘要,正文仍然发文字。
这样体验最好。
文字负责完整信息。
语音负责快速提醒和结论。
十五、TTS 工具什么时候该用,什么时候不该用?
适合用 TTS 的场景
- 任务完成提醒
- 简短状态播报
- 每日摘要
- 家庭或个人助手提醒
- 文章摘要朗读
- 移动中不方便看屏幕
- 需要更有陪伴感的互动
不适合用 TTS 的场景
- 代码块
- 密钥、token、密码
- 很长的 Markdown 表格
- 大段日志
- 错误堆栈全文
- 生产环境敏感告警细节
- 群聊里频繁自动播报
这里尤其要强调敏感信息。
不要让 Agent 把 token、密码、私密配置读成语音。
语音在空间里是“可被听见”的。
这和文字不一样。
十六、适合新手的 TTS 提问模板
下面这些句式可以直接复制。
1)一次性语音测试
1 | /tts audio 你好,这是一条 OpenClaw 语音测试。 |
2)把最新回复转语音
1 | /tts latest |
3)只在当前聊天开启
1 | /tts chat on |
4)当前聊天关闭语音
1 | /tts chat off |
5)让 Agent 生成适合语音的摘要
1 | 请把刚才的结果整理成 30 秒以内适合语音播报的摘要。 |
6)避免读敏感信息
1 | 请用语音总结结果,但不要读出任何 token、路径中的用户名、密钥或完整错误堆栈。 |
7)任务完成后语音提醒
1 | 任务完成后,用一句简短语音告诉我结果。失败时只读结论和下一步建议。 |
这些模板的关键是:
告诉 Agent:语音要短、要有边界、不要读敏感内容。
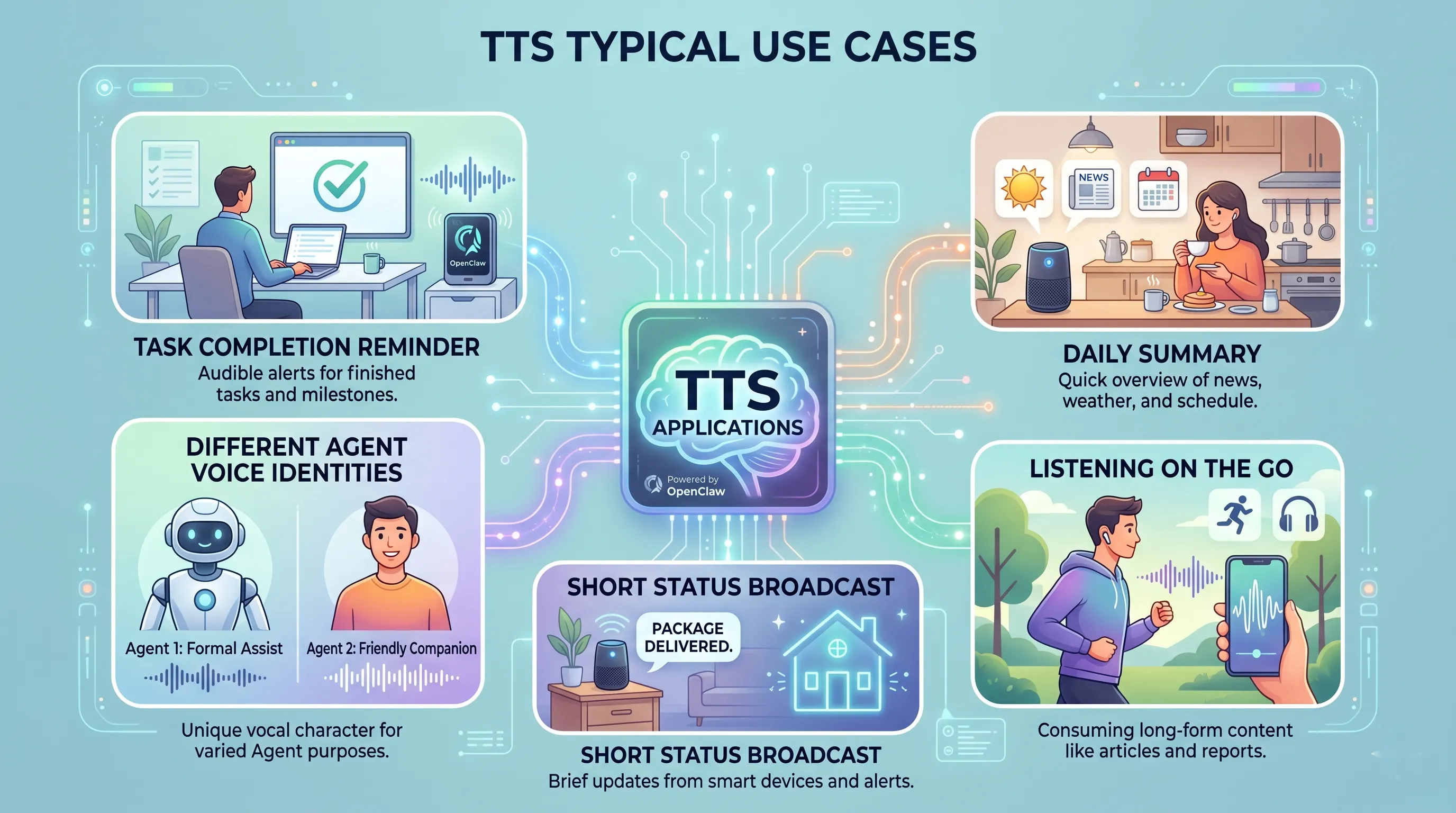
图:TTS 最适合用于任务完成提醒、每日摘要、移动中收听、短状态播报和个性化 Agent 声音。
十七、常见坑
坑 1:一上来就全局开启 always
如果所有回复都自动语音,很快就会烦。
尤其是群聊和高频任务。
更好的做法是:
先用
/tts audio测试,再用/tts chat on小范围试用。
坑 2:让 TTS 读很长的内容
长内容适合文字,不适合语音。
更好的做法是:
长文发文字,语音只发摘要。
坑 3:把代码和命令读成语音
代码、命令、配置最好保留文字。
语音只说:
1 | 我已经把命令发在文字里,你可以直接复制。 |
坑 4:语音读出敏感信息
比如 token、密码、API key、内部 URL。
这类信息不要进入 TTS 文本。
坑 5:没看 /tts status 就乱改配置
TTS 不出声时,先看状态。
1 | /tts status |
不要一上来就换 provider、改配置、重启服务。
坑 6:不知道渠道显示方式不同
同一段 TTS,在 Telegram 可能像语音消息,在另一个渠道可能是音频附件。
这是正常的。
由渠道能力决定。
十八、TTS 的安全边界
TTS 不只是技术功能,也涉及隐私和使用体验。
1)敏感信息不要读出来
语音可能被旁边的人听到。
所以不要读:
- 密码
- token
- API key
- 身份证、手机号等隐私
- 内部系统地址
- 完整错误堆栈里的敏感路径
2)群聊里少用自动语音
群聊里的语音会打扰很多人。
除非群成员明确需要,否则不建议自动 TTS。
3)深夜少发语音
文字可以静默看。
语音更有存在感。
如果做定时任务或 Heartbeat,尤其要注意不要滥发语音。
4)生产告警要短
生产告警可以语音提醒,但不要读完整日志。
更好的格式是:
1 | 告警:网关健康检查失败。建议先查看 gateway status 和最近 50 行日志。 |
这样简洁、有用、不泄露太多。
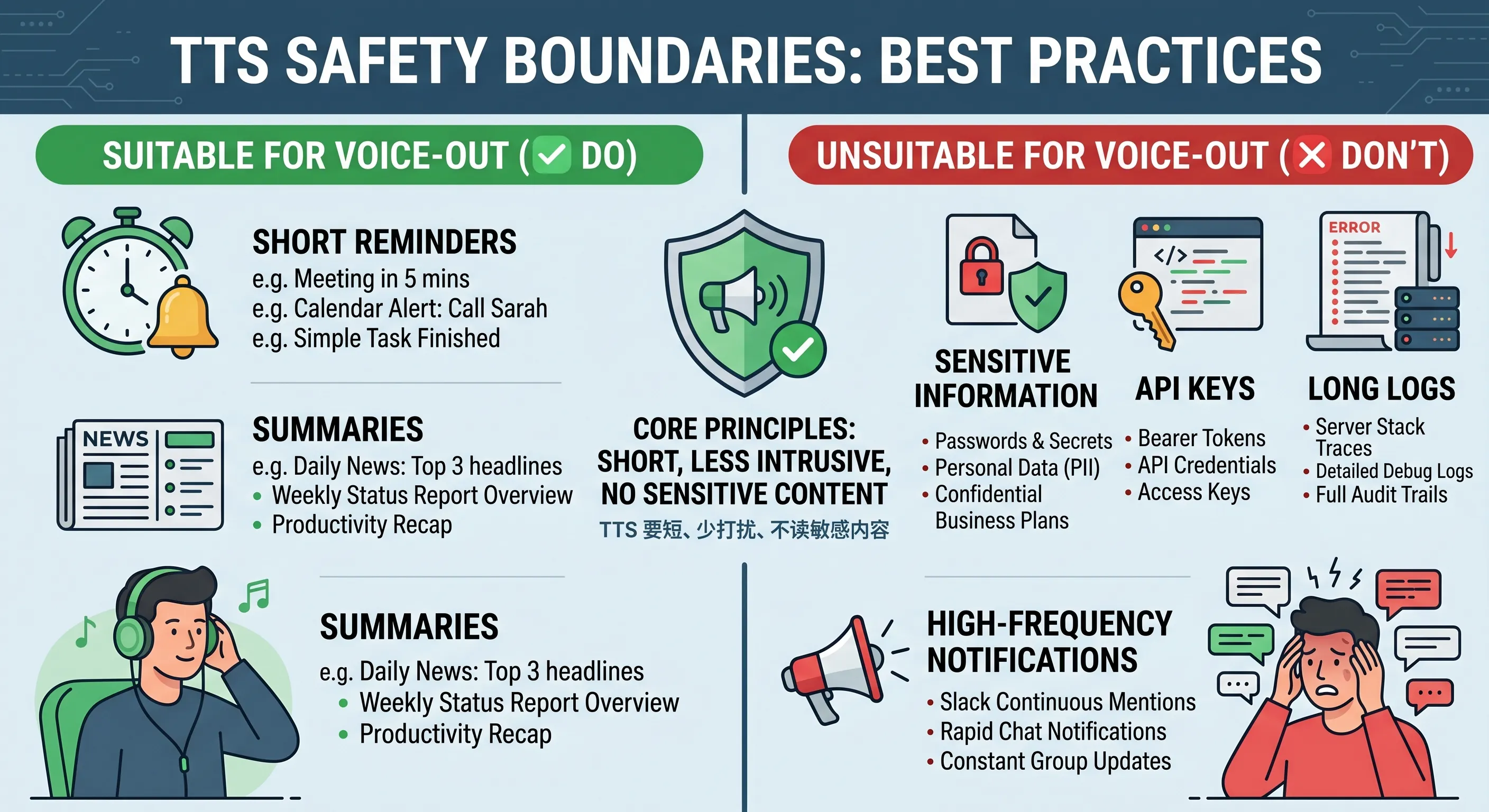
图:TTS 要避免读出敏感信息,也要控制打扰范围。语音适合短提醒,不适合长日志和密钥内容。
十九、这一课最值得记住的一句话
如果今天只记一句话,我建议你记这句:
TTS 不是把所有文字都读出来,而是把适合听的内容变成语音。
再补一句使用原则:
语音要短,敏感不读,默认少打扰。
二十、总结
今天这节课,我们讲清楚了 OpenClaw 的 TTS 语音能力:
- TTS 是 Text-to-Speech,也就是文字转语音。
- OpenClaw 可以把回复转成 voice note 或音频附件。
- Auto-TTS 默认关闭,普通聊天不会自动变语音。
/tts audio <text>适合做一次性语音测试。/tts status是排查 TTS 问题的第一步。- provider 是语音引擎,persona 是稳定的声音身份。
- 不同渠道会以 voice note 或音频附件形式发送。
- 长回复更适合先总结再转语音。
- 不要让 TTS 读出密码、token、密钥或长日志。
- TTS 最适合短提醒、摘要、状态播报和移动中收听。
到这里,第三模块「工具与技能」就告一段落了。
你已经理解了:
- Skill:让 Agent 有稳定方法
- exec:让 Agent 执行命令
- browser:让 Agent 操作网页
- read / write / edit:让 Agent 处理文件
- TTS:让 Agent 开口说话
这些能力组合起来,OpenClaw 就不只是一个聊天入口,而开始像一个真正能做事、能反馈、能陪你一起推进任务的操作系统。
下一课预告
下一课开始,我们进入第四模块:多 Agent 与自动化。
第 16 课会讲:
sessions_spawn:怎么派生子 Agent
也就是:
- 为什么要派生子 Agent
- 子 Agent 和当前对话有什么关系
- 什么任务适合交给子 Agent
- context=”isolated” 和 context=”fork” 怎么理解
- 怎么避免多 Agent 乱跑
🦞 本文由八条撰写,持续更新中。