我为什么不再只用 ChatGPT,而是开始搭自己的 Agent
我为什么不再只用 ChatGPT,而是开始搭自己的 Agent
Kai
过去一年,我越来越少把 AI 当成一个“问答窗口”来用。
不是因为 ChatGPT 不好用。恰恰相反,它已经足够好,好到我开始意识到另一个问题:如果一件事每周都要做、每次都要复制资料、切换网页、保存文件、再发给别人,那它就不应该只停留在聊天框里。
ChatGPT 更像一个很聪明的临时顾问。你问,它答;你贴资料,它分析;你要求改写,它改写。这个模式适合临时问题,但一旦进入真实工作流,就会暴露出几个很明显的摩擦:
- 上次说过的背景,下次还要再说一遍;
- 生成的结果,还要我手动复制到文件、文档、消息软件;
- 查资料、读网页、跑命令、看日志,仍然要我在多个窗口之间来回切;
- 每天、每周重复的任务,AI 不能自己到点开始;
- 它能“建议我做什么”,但不能真的帮我把事做完。
所以我后来开始搭自己的 Agent。
这里说的 Agent,不是一个更会聊天的机器人,而是一个能连接工具、记住偏好、执行步骤、验证结果、定时工作的 AI 工作台。OpenClaw / Hermes 这类系统的价值,也正在这里。
它不是替代 ChatGPT,而是把 AI 从“对话能力”推进到“工作能力”。
一、ChatGPT 解决的是“这一问”,Agent 解决的是“这一类事”
先说一个很日常的例子。
如果我只是问:
帮我写一篇关于 AI Agent 的文章大纲。
ChatGPT 很适合。
但如果我的真实需求是:
每周帮我找 5 个 Agent 相关选题,查资料,筛掉重复内容,写成博客草稿,保存成 Markdown,再把文件发到 Telegram,让我审核。
这已经不是一个“问题”了,而是一条工作流。
这条工作流里至少有这些动作:
- 搜索资料;
- 阅读网页;
- 判断哪些内容值得写;
- 按我的写作风格组织文章;
- 生成 Markdown 文件;
- 保存到指定目录;
- 发给我;
- 下次继续沿用同样标准。
ChatGPT 可以参与其中的一步或几步,但它默认并不拥有完整工作现场。你需要不断把上下文搬给它。
Agent 的思路正好相反:不是让人围着 AI 窗口转,而是让 AI 进入你的工作环境。
二、我真正需要的不是“更聪明”,而是“更少搬运”
很多人讨论 AI 时,喜欢比较模型智商:哪个模型推理更强,哪个模型写作更好,哪个模型代码能力更强。
这些当然重要,但用久了会发现,真实效率的瓶颈经常不在模型聪不聪明,而在“搬运”。
比如写一篇文章:
- 我打开浏览器查资料;
- 把链接复制给 AI;
- AI 总结后,我再复制到编辑器;
- 让它改成博客格式;
- 再复制到本地文件;
- 再想配图;
- 再把文件发到手机或消息平台。
每一步都不难,但每一步都打断注意力。
Agent 的价值,就是减少这些“人肉胶水”。
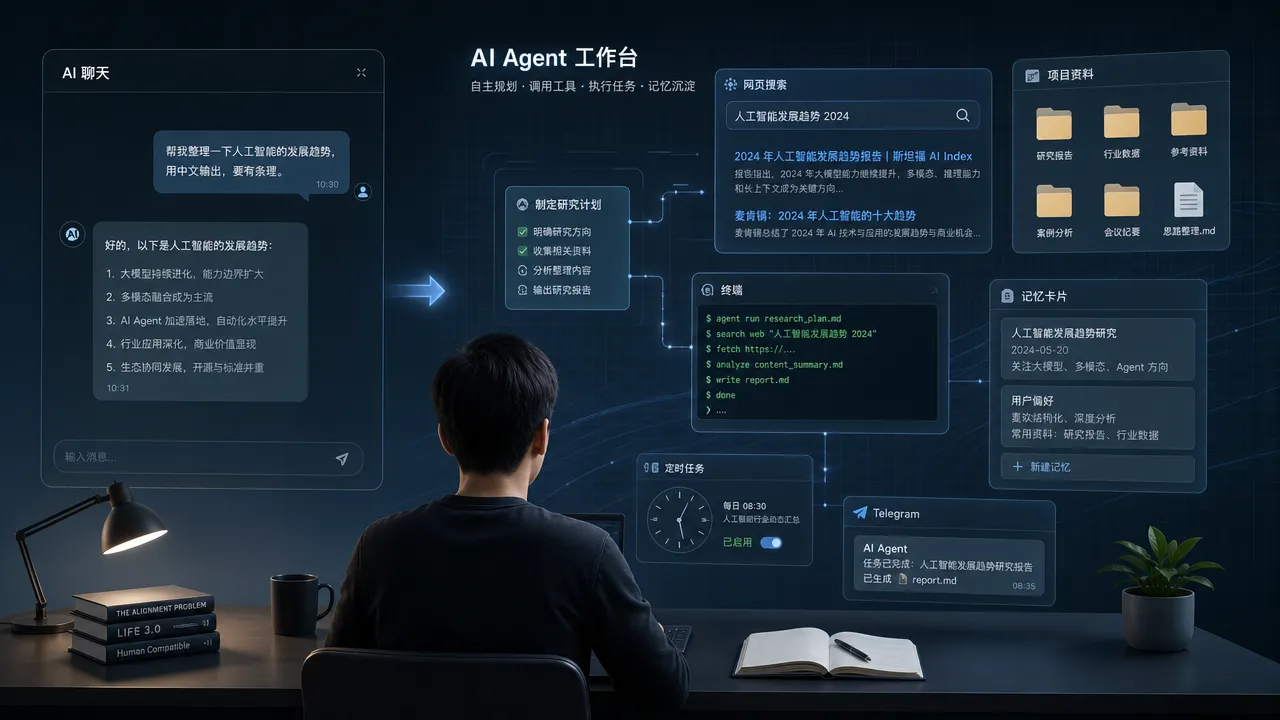
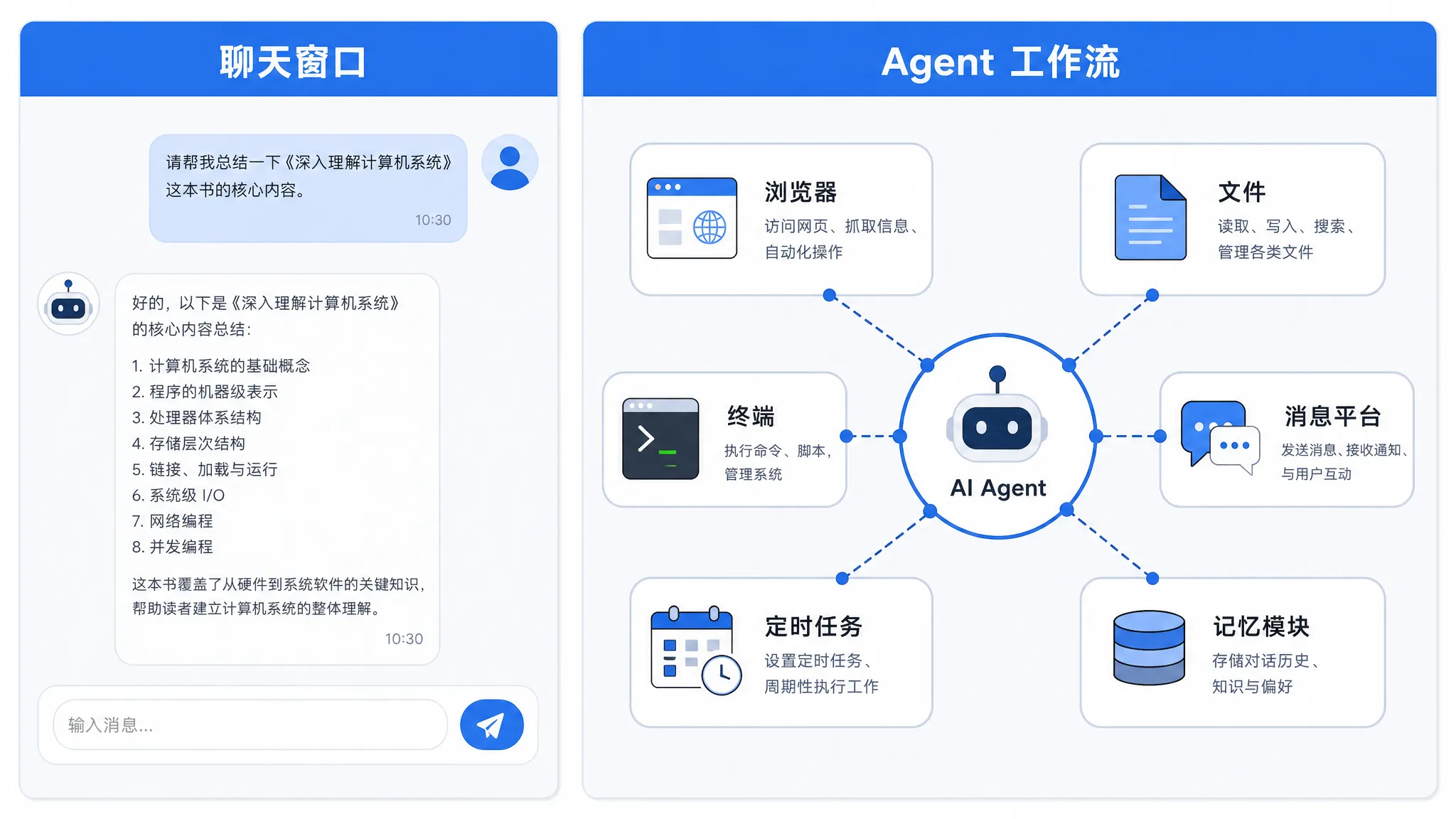
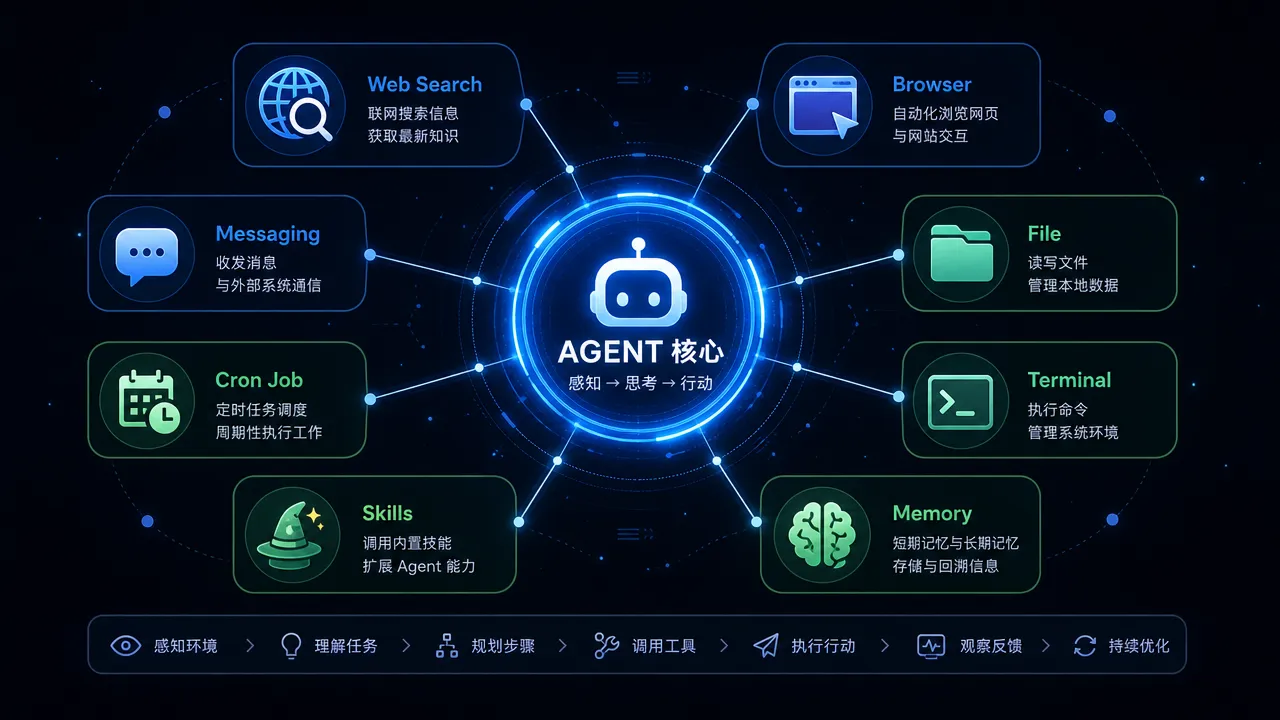
在 Hermes 里,工具不是摆设。它可以通过工具做这些事:
- 用 Web 工具查资料;
- 用 Browser 工具打开网页、点击、查看页面;
- 用 File 工具读写文件、搜索内容、打补丁;
- 用 Terminal 工具跑命令、检查系统状态;
- 用 Memory 记住稳定偏好;
- 用 Skills 复用已经沉淀好的流程;
- 用 Cron Job 定时触发任务;
- 用 Messaging 把结果发回 Telegram、Discord、Slack 等平台。
也就是说,Agent 不只是“生成一段文字”,它更像一个能进工作台的助手。
三、Agent 的核心不是自动化,而是“带判断的自动化”
听到自动化,很多人会想到脚本。
脚本当然重要,但脚本通常适合规则明确的事:
- 每天备份某个目录;
- 定时拉取 RSS;
- 检查端口是否存活;
- 把 CSV 转成固定格式。
问题是,很多工作并没有那么固定。
比如“帮我筛选今天值得关注的 AI 新闻”。这个任务里有大量判断:
- 哪些新闻只是营销稿?
- 哪些内容和我的读者有关?
- 哪些已经被写烂了?
- 哪些适合做深度文章?
- 哪些只适合一句话带过?
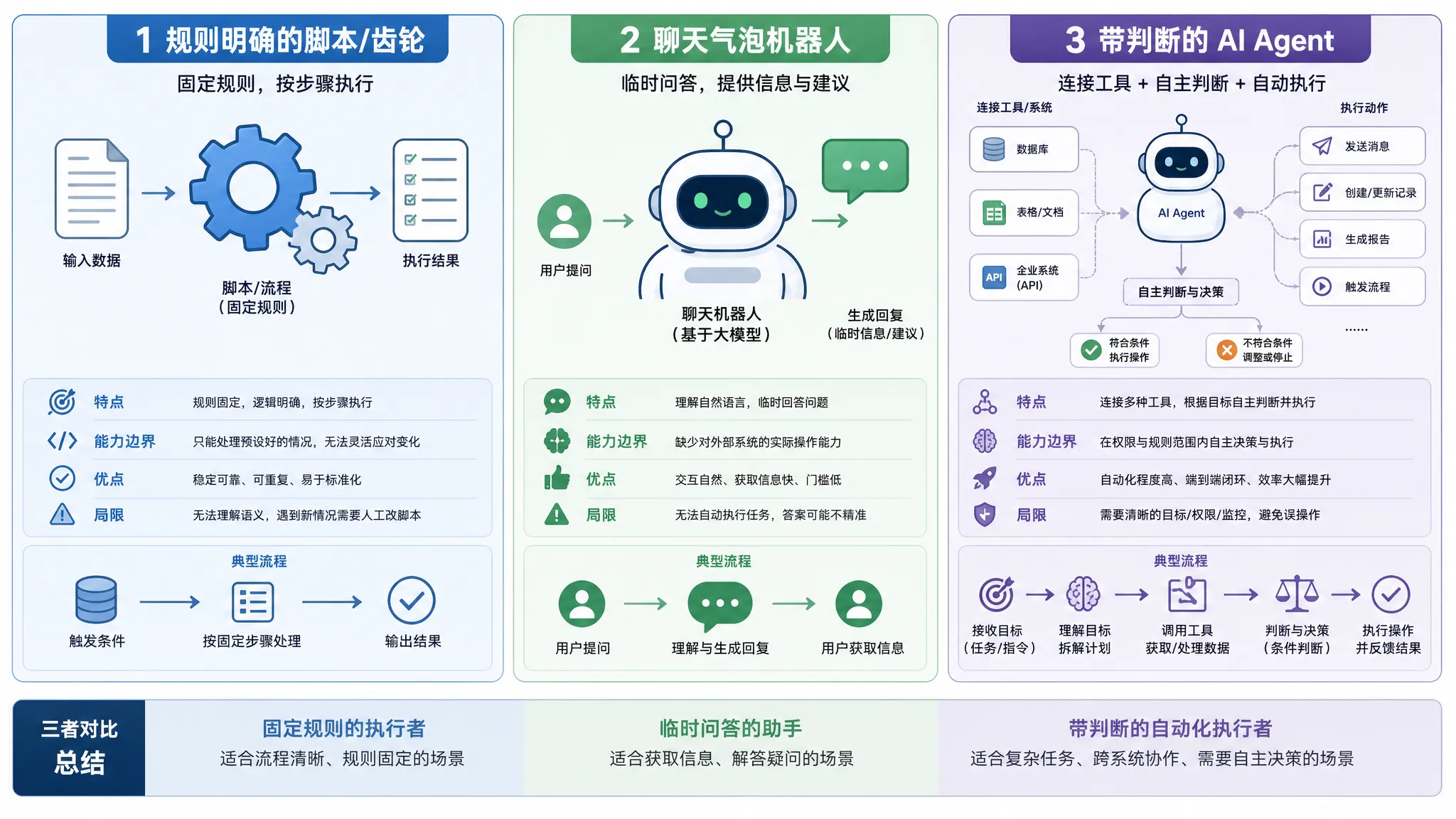
这类任务,纯脚本很难写死规则,纯聊天又不能自动执行。
Agent 正好站在中间:
- 重复步骤交给工具;
- 判断标准交给模型;
- 稳定经验沉淀成 Skill;
- 高风险动作保留人工确认。
所以我更愿意把 Agent 看成“带判断的自动化”,而不是“会自己乱跑的 AI”。
它不是越自主越好,而是越能在合适边界内完成任务越好。
四、一个最小可用 Agent 工作台长什么样
不用一上来就做复杂系统。真正能长期用起来的 Agent,往往从一个很小的工作台开始。
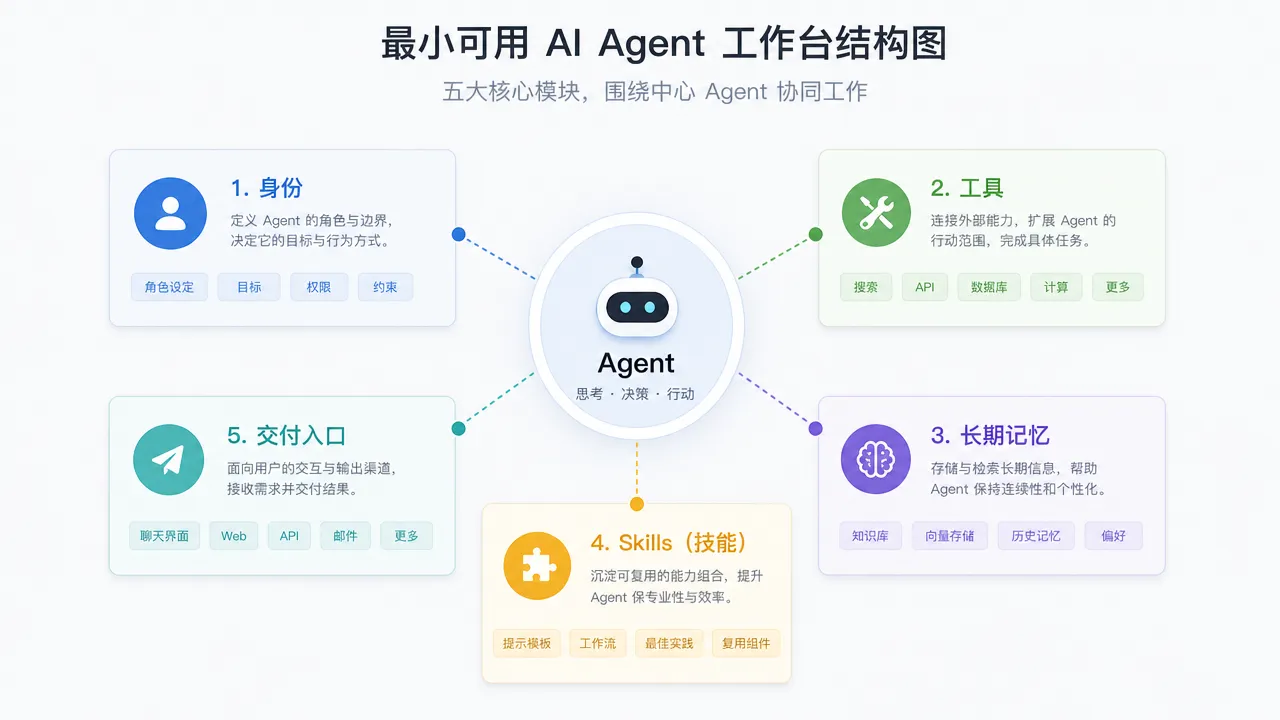
我建议先搭这 5 个能力。
1. 一个明确身份:它到底负责什么
不要一开始就幻想“全能 AI 助手”。
更好的方式是先给它一个明确角色:
- 写作助手:负责选题、资料整理、文章初稿;
- 代码助手:负责读代码、修 Bug、跑测试;
- 运维助手:负责看日志、查状态、写日报;
- 研究助手:负责追踪论文、项目、技术动态;
- 个人助理:负责提醒、总结、资料归档。
在 Hermes 里,可以通过 Profile 把不同 Agent 分开。Profile 不是一个简单昵称,而是一套独立状态:配置、密钥、人格文件、记忆、会话、Skills、Cron Jobs 都可以隔离。
这很重要。
写作助手不应该记住服务器运维细节;运维助手也不应该混进公众号写作风格。角色越清楚,长期表现越稳定。
2. 一组可控工具:它能做什么,不能做什么
Agent 的能力来自工具,但风险也来自工具。
一个写作型 Agent,可能只需要:
- web:查资料;
- file:保存文章;
- memory:记住写作偏好;
- skills:加载写作流程;
- messaging:把结果发给我。
一个开发型 Agent,可能还需要:
- terminal:跑测试;
- browser:复现网页问题;
- delegation:把代码审查、资料检索分给子 Agent。
工具不是越多越好。工具越多,Agent 的行动空间越大,越需要边界。
3. 一套长期记忆:只记真正稳定的东西
长期记忆很容易被滥用。
我不希望 Agent 记住“今天写了哪篇文章”“某个临时文件路径”“某次报错日志”。这些东西过几天就没用了,留在记忆里反而污染判断。
真正该记的是稳定事实:
- 我偏好中文交流;
- 我的博客地址;
- 文章默认保存目录;
- 我喜欢什么样的写作风格;
- 某个项目长期使用的测试命令;
- 某个环境里稳定存在的工具约定。
Hermes 的记忆是有边界的,不是无限塞东西。这个设计反而是优点:它逼着你把“长期事实”和“临时任务”分开。
4. 一批 Skills:把经验写成可复用流程
如果说 Memory 记的是“事实”,那 Skill 记的就是“做法”。
比如:
- 如何写一篇 OpenClaw / Hermes 中文教程;
- 如何做一次 GitHub PR Review;
- 如何把 YouTube 视频整理成文章;
- 如何生成适合公众号的配图提示词;
- 如何检查文章是否包含 front matter、配图、总结、常见坑。
Skill 的价值不是让 AI 背更多知识,而是减少你每次重新交代流程。
当一个任务反复出现,就应该考虑把它沉淀成 Skill。
5. 一个交付入口:结果回到你常用的地方
很多 AI 工具最大的问题是“结果留在工具里”。
而我真正需要的是:
- 文章保存成
.md文件; - 报告发到 Telegram;
- 定时任务结果送到指定聊天;
- 文件能被我直接下载;
- 关键动作完成后有可验证的输出。
这也是我喜欢把 Agent 接到 Telegram 这类消息平台的原因。它不只是聊天入口,也是交付入口。
五、实操:从一个“文章助手 Agent”开始
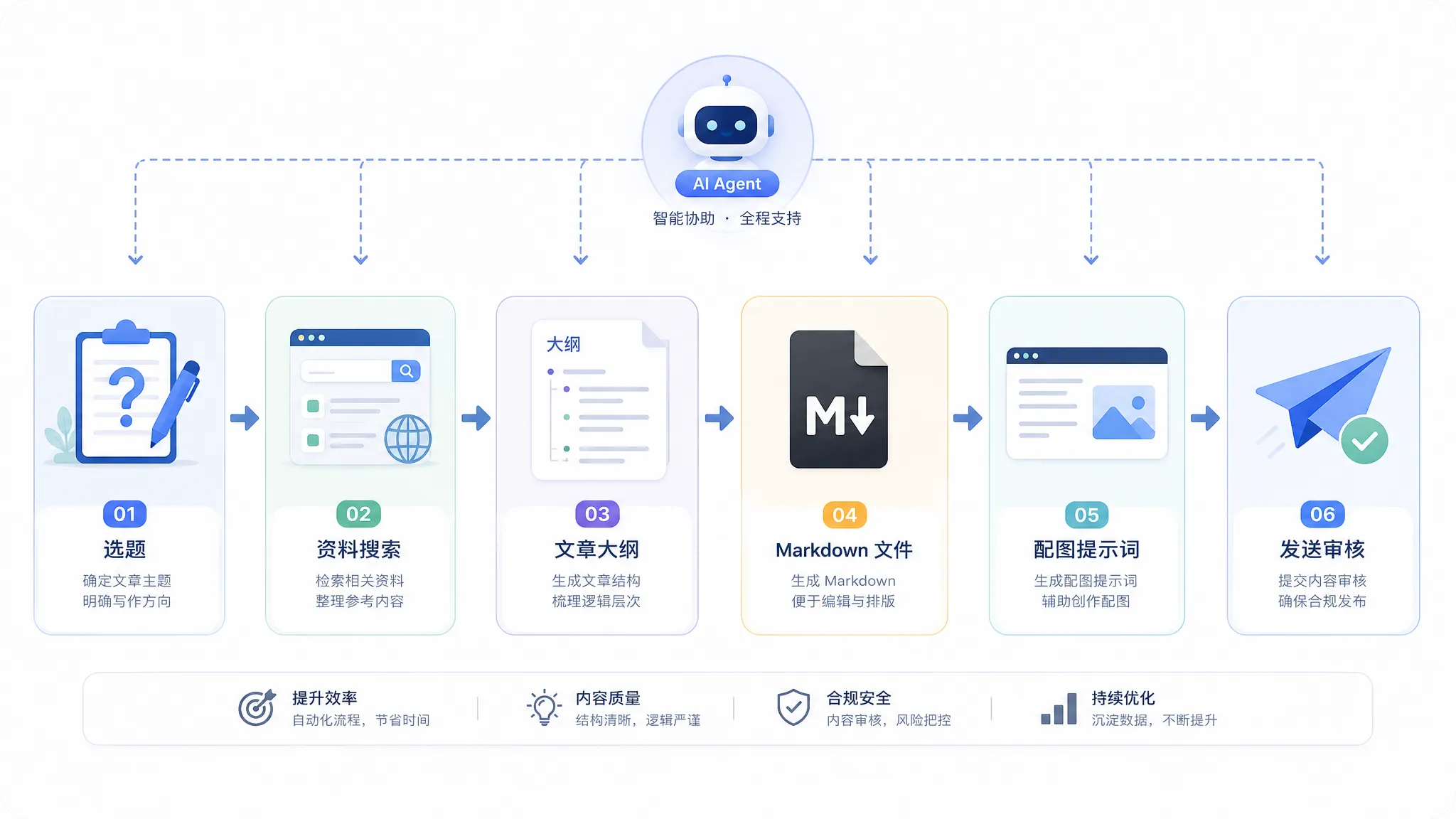
下面给一个非常具体的落地思路。它不追求炫技,只追求能长期用。
目标是搭一个文章助手 Agent:
输入一个选题,它能帮我查资料、写大纲、生成 Markdown 草稿、给出配图提示词,并把文件发给我审核。
第一步:先定义边界,而不是先装工具
先写清楚它的工作边界:
1 | 你是一个中文技术文章助手。 |
这段话看起来像提示词,但它更像 Agent 的“岗位说明书”。
如果长期使用,可以放到对应 Profile 的人格文件或工作规范里。这样每次启动,它都知道自己是谁,应该怎么做。
第二步:只开放必要工具
对文章助手来说,一开始不需要给太多权限。
可以先保留:
1 | hermes chat --toolsets "web,file,skills,memory,messaging" |
如果需要查本地项目文档,再加入 terminal 或 search/file 相关能力。
如果只是写作,不要轻易给它高风险系统权限。能读写文章目录就够了,没必要让它碰所有生产目录。
第三步:把一次满意的写作流程沉淀成 Skill
比如你发现一套流程很好用:
- 先确认文章定位;
- 再搜索资料;
- 再列大纲;
- 写初稿;
- 自查是否有 AI 腔;
- 补实操步骤;
- 补配图建议;
- 保存为 Markdown;
- 发给用户审核。
这就应该写进 Skill,而不是每次重新说。
Skill 不需要玄学,关键是清楚:
- 什么时候使用;
- 具体步骤是什么;
- 哪些坑不能踩;
- 完成后如何验证。
这一步是从“我会用 AI”到“我在训练自己的工作系统”的分界线。
第四步:让交付物可验证
Agent 写完文章,不应该只说“我写好了”。
更好的结果是:
- 文件保存到明确路径;
- 文件大小非零;
- front matter 存在;
- 至少有 6 个配图占位;
- 包含配图提示词;
- 最后把
.md文件发回来。
这点非常重要。
一个靠谱的 Agent,不是“回答听起来像完成了”,而是“能拿出可检查的结果”。
六、进一步:让 Agent 每天准时上班
当一个流程稳定后,就可以考虑定时任务。
比如:
- 每天早上 8 点整理 AI 热点;
- 每周一给出 5 个公众号选题;
- 每天晚上总结当天收藏的链接;
- 每周检查一次博客文章草稿目录;
- 每天推送服务器状态和异常日志。
Hermes 里可以用 Cron Job 做这类事。它支持一次性或周期性任务,也可以把结果交付到原聊天、平台目标或本地文件。
一个很直观的自然语言任务是:
1 | Every morning at 9am, check Hacker News for AI news and send me a summary on Telegram. |
也可以用命令创建:
1 | hermes cron create "every 1d at 09:00" "检查今天值得关注的 AI Agent 新闻,筛掉营销内容,给我 5 条中文摘要和 3 个文章选题。" |
但这里有一个关键提醒:定时任务一定要写得自包含。
因为定时运行时,通常不会有人在旁边补充背景。你要在任务说明里写清楚:
- 查什么;
- 排除什么;
- 输出格式是什么;
- 发到哪里;
- 如果没有新内容怎么办;
- 禁止做什么。
例如:
1 | 每天早上 9 点运行。搜索过去 24 小时 AI Agent、Hermes、OpenClaw、MCP 相关动态。 |
这样的 Agent 才像一个稳定员工,而不是一个每天自由发挥的实习生。

七、我不会让 Agent 做的几类事
搭 Agent 不是把所有权限都交出去。
我反而建议,一开始要非常保守。
1. 不让它自动公开发布
写文章可以,生成公众号草稿可以,但真正发布最好人工确认。
原因不是 AI 写不好,而是公开发布涉及品牌、事实、版权、语气和时机。越是对外动作,越应该有人类最后过一遍。
2. 不让它复述敏感信息
API Key、Bot Token、数据库密码、OAuth Token,这些东西即使工具里能看到,也不应该出现在回答里。
一个好的 Agent 系统应该默认做密钥遮蔽,但使用者也要有意识:不要要求它“把所有环境变量发我看看”。
3. 不让它在没验证时宣称完成
比如它说:
已经保存文件。
那就应该检查文件是否存在。
它说:
测试通过。
那就应该给出真实测试输出。
它说:
已发送。
那就应该能说明发送目标或返回结果。
Agent 时代,最重要的不是“会不会说”,而是“有没有证据”。
4. 不把 Profile 当沙箱
很多人会误以为:我建了一个新 Profile,它就不能碰外面的文件了。
这不准确。
Profile 隔离的是 Hermes 的状态,比如配置、记忆、会话、Skills、Cron Jobs。它不等于系统级沙箱。在默认本地终端后端下,Agent 仍然拥有当前系统用户的文件权限。
如果你真的要隔离执行环境,应该考虑 Docker、SSH 远程环境或更严格的权限设计。

八、什么时候继续用 ChatGPT,什么时候该搭 Agent
我现在不会把所有事情都丢给 Agent。
如果只是:
- 问一个概念;
- 翻译一段话;
- 改写一个标题;
- 临时分析一段材料;
- 头脑风暴几个想法;
ChatGPT 已经足够好,没必要复杂化。
但如果出现下面几个信号,我会考虑搭 Agent:
- 这个任务每周都会重复;
- 每次都要用同一套标准;
- 需要读写文件;
- 需要查资料并保存结果;
- 需要连接消息平台;
- 需要定时运行;
- 需要记住我的偏好;
- 需要执行后验证,而不是只给建议。
一句话:
临时问题,用 ChatGPT;稳定流程,搭 Agent。
这也是我使用 AI 的一个重要变化。
以前我在找“更好的回答”。现在我更在意“更好的系统”。
九、一个可以直接照着做的 Agent 搭建清单
如果你也想开始,不建议一上来就追求全自动。可以按这个清单走。
第 1 步:选一个高频场景
不要选太大的目标,比如“帮我管理全部工作”。
选一个小而痛的场景:
- 每周生成选题;
- 每天整理新闻;
- 每次写文章都生成配图提示词;
- 每天检查服务器状态;
- 每周总结 GitHub 项目动态。
第 2 步:写一段岗位说明书
回答这几个问题:
- 它是谁?
- 服务谁?
- 默认语言是什么?
- 输出格式是什么?
- 哪些事情禁止做?
- 什么时候必须查资料?
- 什么时候必须让人确认?
这比写一堆华丽提示词更重要。
第 3 步:只给必要工具
先从最少工具开始。
写作型:
1 | hermes chat --toolsets "web,file,skills,memory,messaging" |
开发型:
1 | hermes chat --toolsets "terminal,file,skills,session_search,delegation" |
研究型:
1 | hermes chat --toolsets "web,browser,file,skills,memory" |
这些只是示例,实际要根据你的环境和风险承受能力调整。
第 4 步:把好流程沉淀成 Skill
当你连续 3 次用同一种方式完成任务,就该考虑写 Skill。
Skill 不是为了炫耀“我有很多能力”,而是为了避免重复教学。
第 5 步:加入验证步骤
每个任务最后都问一句:
怎么证明它真的完成了?
文章任务看文件;代码任务跑测试;发送任务看返回结果;定时任务看下一次运行记录。
没有验证的 Agent,很容易变成“会说漂亮话的自动补全”。
第 6 步:再考虑定时化
只有当手动流程稳定后,才适合做 Cron Job。
否则你只是把不稳定流程变成了每天自动发生的不稳定。
十、真正的变化:从使用工具,到拥有工作系统
我为什么不再只用 ChatGPT?
不是因为它不强,而是因为我已经不满足于“让 AI 回答我”。
我更希望 AI 能进入一个清楚的工作系统:
- 知道自己是谁;
- 知道我的偏好;
- 能使用合适工具;
- 能把经验沉淀下来;
- 能按时间运行;
- 能把结果交付给我;
- 能在关键动作前停下来让我确认;
- 能用真实输出证明它完成了任务。
这就是 Agent 和聊天机器人的区别。
聊天机器人像一个随叫随到的顾问。
Agent 更像一个有岗位、有工具、有流程、有交付标准的工作伙伴。
当然,它还不完美。它会犯错,会误解任务,会需要边界,也需要人来设计流程。
但这恰恰说明,未来真正重要的能力可能不是“会不会写提示词”,而是:
你能不能把自己的工作,拆成 AI 可以理解、可以执行、可以验证、可以长期复用的系统。
这件事,比单次问答更慢,但也更值钱。
常见坑
坑 1:一上来就追求全自动
全自动听起来很酷,但最容易失控。建议先做人机协作,再逐步自动化。
坑 2:把临时信息塞进长期记忆
长期记忆应该保存稳定事实,不要保存一次性的任务进度、临时报错、过期链接。
坑 3:给太多工具权限
工具越多,Agent 的能力越强,风险也越高。先从最少工具开始,用到再加。
坑 4:没有验证步骤
“我已经完成了”不是证据。文件、命令输出、发送结果、运行记录,才是证据。
坑 5:把 Profile 当成安全沙箱
Profile 主要隔离 Agent 状态,不等于限制系统文件权限。需要安全隔离时,要考虑 Docker、SSH、容器或系统权限设计。
安全边界
搭 Agent 时,我建议默认遵守这几条:
- 不让 Agent 自动公开发布内容,发布前必须人工确认;
- 不让 Agent 复述 API Key、Token、密码等敏感信息;
- 涉及删除、覆盖、批量修改文件时必须确认范围;
- 定时任务必须自包含,不能递归创建新的定时任务;
- 高风险工具按场景开启,不做“全权限默认开”;
- 对外发送消息前,明确发送目标和内容边界;
- 重要任务必须有可验证交付物。
总结
ChatGPT 适合回答问题,Agent 适合承接流程。
如果你的需求只是临时问答,聊天窗口已经很好。但如果你开始频繁做同一类事,需要查资料、读文件、保存结果、发送消息、定时运行、复用经验,那就值得搭自己的 Agent。
真正有价值的不是“AI 更像人”,而是它能不能进入你的工作系统,成为一个有边界、有工具、有记忆、有交付的协作者。
我的建议是:不要从大而全的 AI 助理开始。先选一个高频、低风险、可验证的小场景,把它跑通。等流程稳定,再沉淀 Skill,再考虑定时任务和多 Agent 协作。
这比单纯追逐新模型,更接近 AI 的长期价值。
🦞 本文由八条撰写,持续更新中。