OpenClaw系列第8课:Context Engine - 模型“看到了什么”

OpenClaw系列第8课:Context Engine - 模型“看到了什么”
Kai这是「OpenClaw 教程课程」第 8 课。
前一课我们讲了 Agent Loop,知道了一条消息会经历一轮完整处理流程。今天继续往里走一步:模型到底看到了什么?
图:Context Engine 决定模型看到哪些信息、以什么顺序看到、哪些内容更重要。
很多人对 AI 的理解还停留在一个很简单的层面:
- 我发一句话
- 模型读到这句话
- 然后回答
但在 OpenClaw 里,事情远没有这么简单。
因为模型看到的,通常根本不只是你刚输入的那一句。
它还可能同时看到:
- 系统提示词
- 角色设定
- 当前 Session 历史
- 工作区里的 bootstrap 内容
- Skills 提供的上下文
- 工具结果摘要
- 当前运行的模式与限制
也就是说:
模型并不是在读“你的这一句话”,而是在读一整份由系统拼装出来的上下文包。
而负责这件事的,就是你今天要理解的核心概念:
Context Engine。
一、先说结论:Context Engine 决定模型到底“看见了什么”
你可以先把 Context Engine 理解成一个很直白的角色:
它是 OpenClaw 在把消息送进模型之前的“上下文装配系统”。
也就是说,当你发出一条消息后,系统不会直接把这句话原样扔给模型。
它通常会先做这些事:
- 找到当前所属 Session
- 读取历史消息
- 加入系统提示词
- 注入工作区上下文
- 加入技能相关说明
- 追加必要的运行信息
- 最终整理出一份“模型实际看到的输入”
所以你以后一定要建立一个习惯:
用户看到的是输入框;模型看到的是 Context Engine 拼出来的一整包内容。
二、为什么需要 Context Engine?
因为如果没有它,OpenClaw 就会退化成非常原始的“单轮消息转模型”系统。
那会带来很多问题:
- 模型不知道自己是谁
- 不知道现在处在哪个 Session
- 不知道之前聊过什么
- 不知道有哪些可用工具
- 不知道工作区里有哪些背景信息
- 不知道这次任务的边界和规则
而 OpenClaw 之所以能表现得“像一个持续存在的 Agent”,靠的并不是模型自己突然变聪明了,而是:
Context Engine 在每一轮运行前,把该给模型看的东西都组织好了。
三、模型看到的内容,通常由哪几部分组成?
你可以先把它粗略拆成 5 大块。
1)系统层信息
这是最上层、最稳定的一层。
通常包括:
- 系统提示词
- 角色和行为边界
- 运行规范
- 输出风格要求
这部分决定了模型是以什么身份、什么规则在回答。
2)会话层信息
也就是当前 Session 中已经发生过的内容。
例如:
- 之前说过什么
- 当前话题是什么
- 这轮回复应该延续哪段历史
这部分决定了它为什么“能接上文”。
3)工作区 / bootstrap 层信息
例如:
- AGENTS.md
- SOUL.md
- USER.md
- 其他工作区注入的背景信息
这部分决定了它为什么会有固定人设、固定风格、固定目标。
4)技能与工具层信息
例如:
- 当前可用 skills
- 当前可用工具
- 工具的能力边界
- 工具返回结果的摘要信息
这部分决定了它不只是“会说”,而且知道“自己能做什么”。
5)当前用户输入
这才是你实际看到的那句话。
所以在真实运行里,用户输入往往只是 Context Engine 最后拼上的一块,而不是全部。
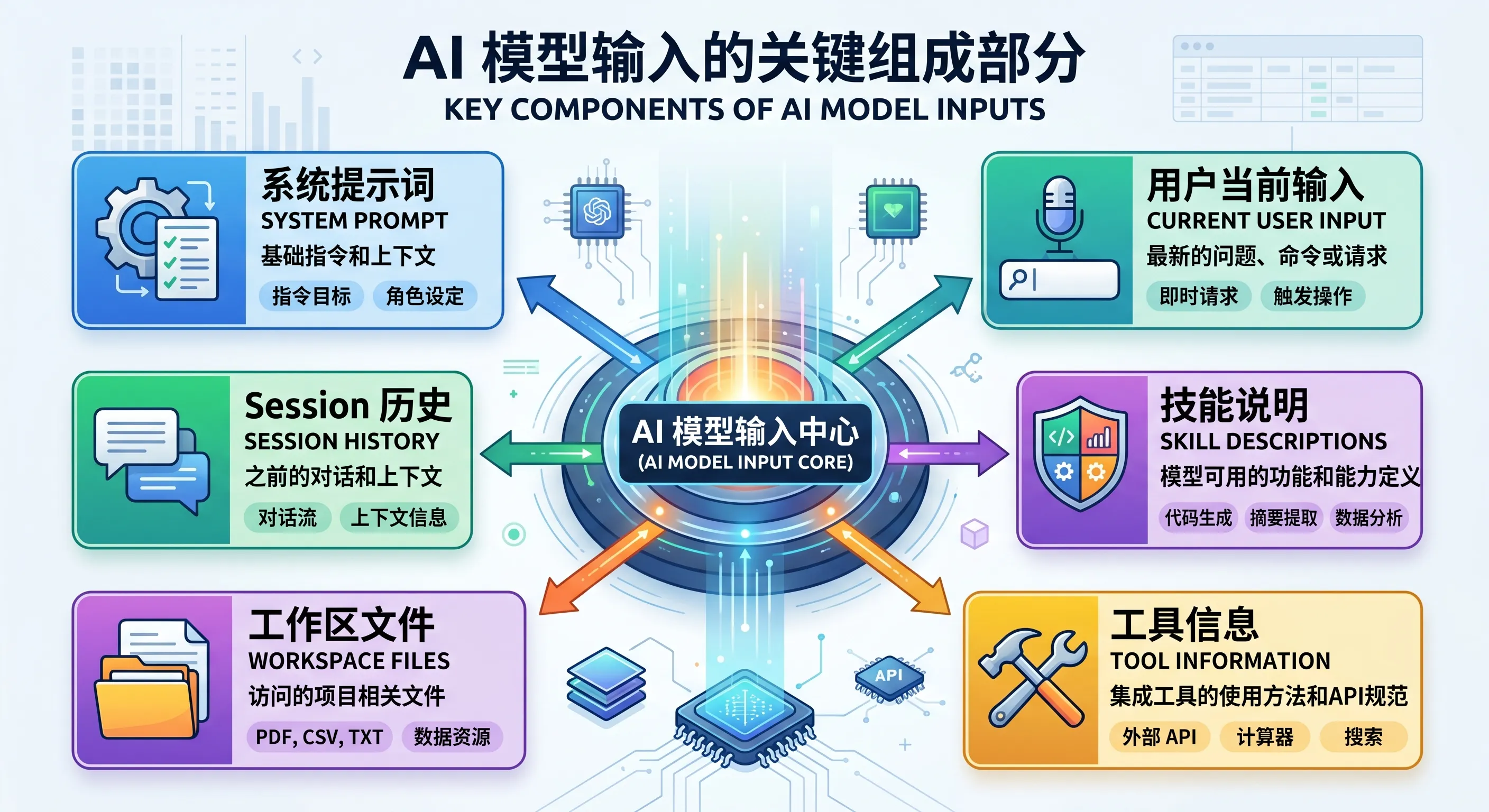
图:模型真正看到的输入,通常是系统提示词、Session 历史、工作区文件、技能与工具信息、当前用户输入一起组成的。
四、为什么同一句话,在不同上下文里会得到完全不同的回答?
这就是 Context Engine 最值得理解的地方。
比如你发同一句:
帮我整理一下
这句话本身其实非常模糊。
但如果放在不同上下文里,模型看到的世界完全不一样。
情况 A:前面刚聊完一篇教程
它会理解成:
- 帮我整理文章结构
情况 B:前面刚执行过工具输出
它可能理解成:
- 帮我整理工具结果
情况 C:当前工作区要求输出 Hexo Markdown
它可能理解成:
- 帮我整理成博客发布格式
所以你会发现:
同一句用户输入,其实不是在真空里解释的,而是在整个上下文包里解释的。
这就是为什么 Context Engine 直接决定回答质量。
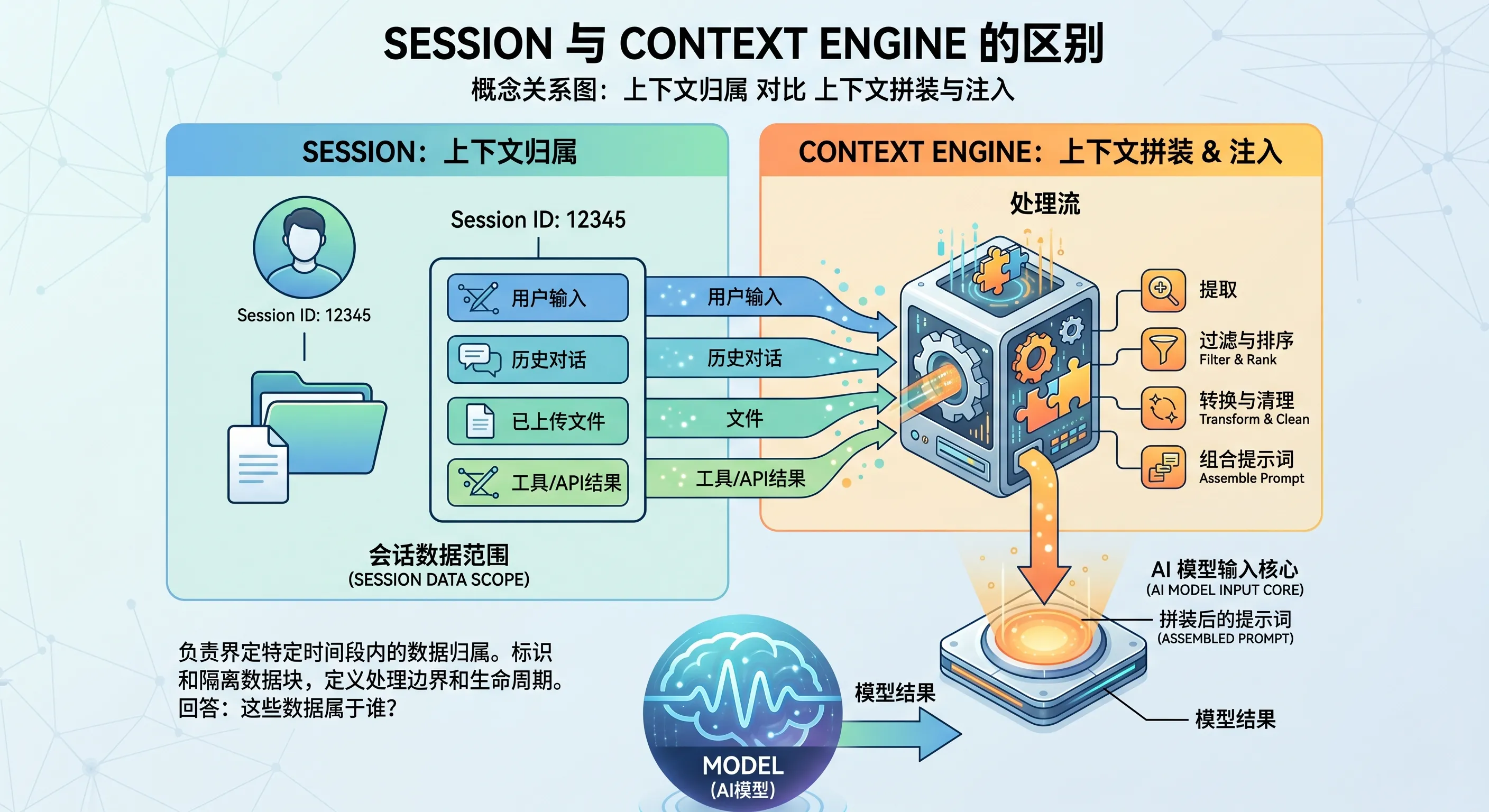
图:同一句输入在不同上下文条件下,会被模型理解成完全不同的任务。
五、为什么说 Context Engine 是 Agent 表现稳定性的关键?
因为 Agent 的“稳定感”其实主要来自上下文稳定,不是来自模型稳定。
比如你会觉得一个 Agent 很稳,通常是因为它:
- 风格稳定
- 目标稳定
- 知道你是谁
- 知道现在做什么
- 不会每次都像失忆一样重新开始
而这些能力,本质上都依赖 Context Engine。
模型本身只是在接收和处理输入。
真正让输入变成“一个可持续角色的工作语境”的,是 Context Engine。
所以换句话说:
Context Engine 决定了这个 Agent 看起来像不像一个持续存在的助手。
六、Context Engine 和 Session 的关系是什么?
你可以把两者这样区分:
Session 决定“这条消息属于哪段上下文”
它解决的是归属问题。
Context Engine 决定“把这段上下文怎么装给模型看”
它解决的是装配问题。
所以你可以理解成:
- Session 像仓库
- Context Engine 像装配线
仓库里有很多材料,但模型不会自己进去翻。
真正把这些材料按顺序、按优先级、按结构整理后送进去的,是 Context Engine。
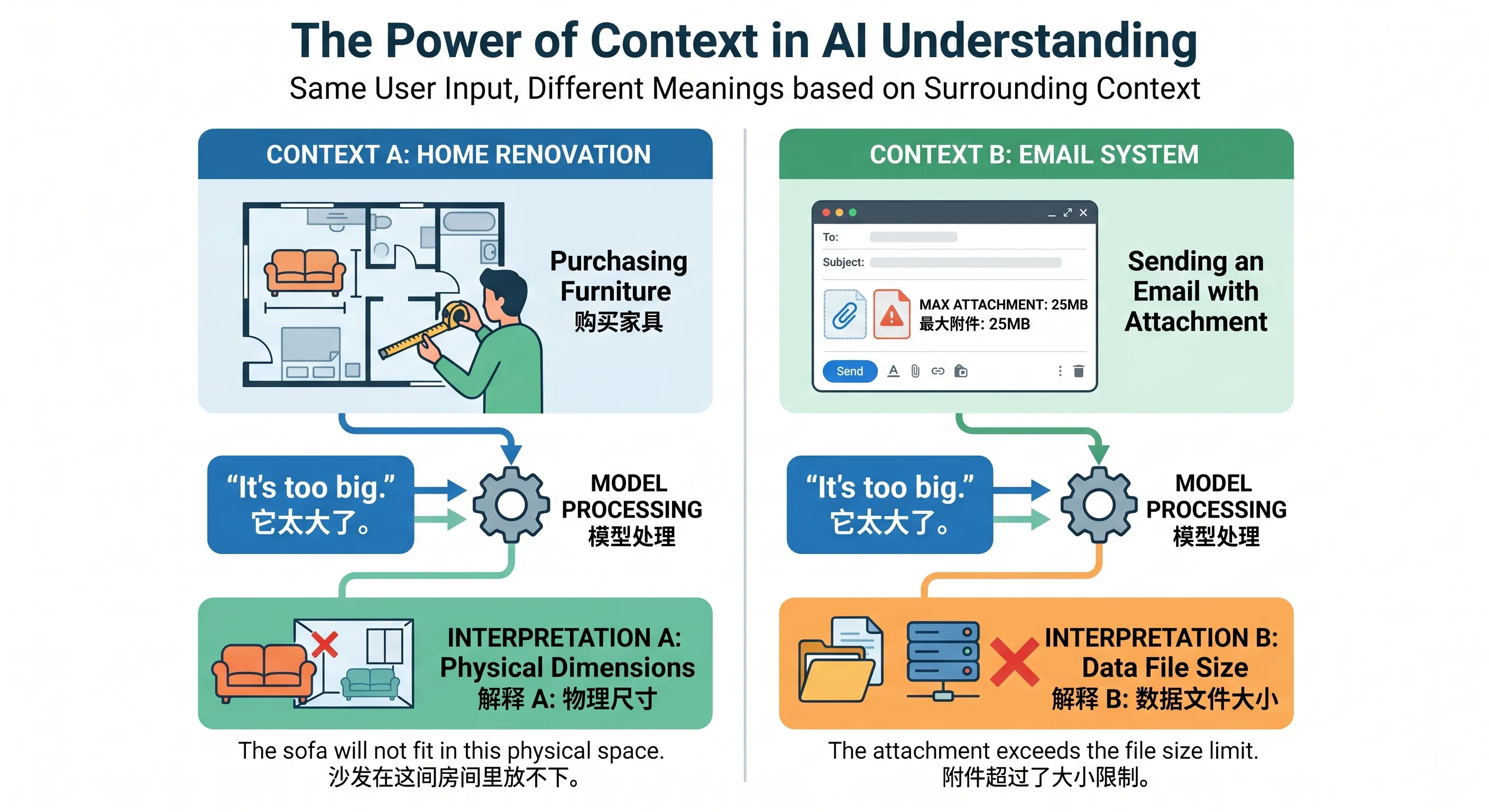
图:Session 决定上下文归属,Context Engine 决定上下文如何被拼装并送进模型。
七、Context Engine 和 Agent Loop 的关系又是什么?
前一课我们讲过:
Agent Loop 是一轮完整的运行过程。
那 Context Engine 在里面处在哪?
你可以理解为,它位于 Agent Loop 的前半段关键位置。
也就是:
- 消息进入系统
- 找到 Session
- Context Engine 开始装配模型输入
- 模型推理
- 工具调用
- 输出结果
所以它不是 Agent Loop 之外的附属物,而是 Agent Loop 里非常核心的一环。
甚至可以说:
没有 Context Engine,Agent Loop 仍然能跑;但它会退化成上下文非常贫瘠、表现非常不稳的系统。
八、为什么“系统提示词”这么重要?
因为系统提示词通常是 Context Engine 里优先级最高的一层之一。
它会决定很多基础行为,比如:
- 角色身份
- 输出语言
- 风格倾向
- 安全边界
- 是否查文档
- 是否先查记忆
也就是说,系统提示词不是“可有可无的背景说明”,而是:
模型进入这轮运行时最重要的行为框架之一。
这也解释了为什么工作区里像这些文件会这么重要:
AGENTS.mdSOUL.mdUSER.md
因为它们往往最终都会进入 Context Engine 的装配链,进而影响模型看到的世界。
九、为什么有时候上下文太多,反而会出问题?
这是理解 Context Engine 后必须进一步知道的一点。
并不是“给模型越多上下文越好”。
如果上下文过多,会带来这些问题:
- 重点被稀释
- 噪音变大
- 模型更容易跑偏
- token 成本升高
- 系统处理变重
所以 Context Engine 的价值,不只是“把东西都塞进去”,而是:
把该给模型看的东西,以合适的结构和优先级放进去。
这也是为什么后面你会遇到:
- compaction
- pruning
- summary
- context trimming
这些概念。
它们本质上都是在解决同一个问题:
上下文不能无限膨胀,必须被管理。
十、你可以把 Context Engine 理解成“给模型准备考卷的人”
这是一个我觉得很好懂的类比。
模型像一个很强的答题者。
但它答得好不好,不只取决于它聪不聪明,也取决于它拿到的题面长什么样。
而 Context Engine 就像那个出卷和装卷的人:
- 题目顺序怎么排
- 哪些背景材料放在前面
- 哪些规则写在最上面
- 哪些历史信息必须附带
- 哪些多余内容要裁掉
所以以后你看到模型回答奇怪,不要只问:
- 这个模型行不行?
你还要问:
- 它到底看到了什么?
这往往是更关键的问题。
十一、这一课最值得记住的一句话
如果今天你只记一句话,我建议你记这句:
Context Engine 决定了模型真正看到的输入,而不是用户输入框本身。
一旦你真的理解了这句话,后面很多现象都会变得很清楚:
- 为什么它能接上文
- 为什么它会保持某种风格
- 为什么同一句话在不同环境里会有不同答案
- 为什么工作区文件会影响它的行为
十二、总结
今天这节课,你只要真正记住下面 5 句话,就够了:
- 模型看到的不是用户刚输入的那一句,而是一整份上下文包。
- Context Engine 就是这份上下文包的装配系统。
- Session 决定上下文归属,Context Engine 决定上下文如何被送进模型。
- 系统提示词、工作区文件、历史对话、技能和工具信息都会影响模型所见。
- 上下文不是越多越好,重点在于正确装配。
下一课预告
下一课我们会学:
第 9 课:Memory 机制——如何让 AI 记住你的事
也就是继续回答一个特别常见的问题:
- 它到底记住了什么?
- Session 记忆和长期记忆有什么区别?
- Memory 文件是怎么工作的?
🦞 本文由八条撰写,持续更新中。